2026年4月24日,DeepSeek发布了V4系列模型的预览版。与此前让英伟达单日市值蒸发近6000亿美元的那次发布不同,这次没有引发股市雪崩,但传出的信号同样尖锐:价格差距已经到了让对手难以忽视的程度。
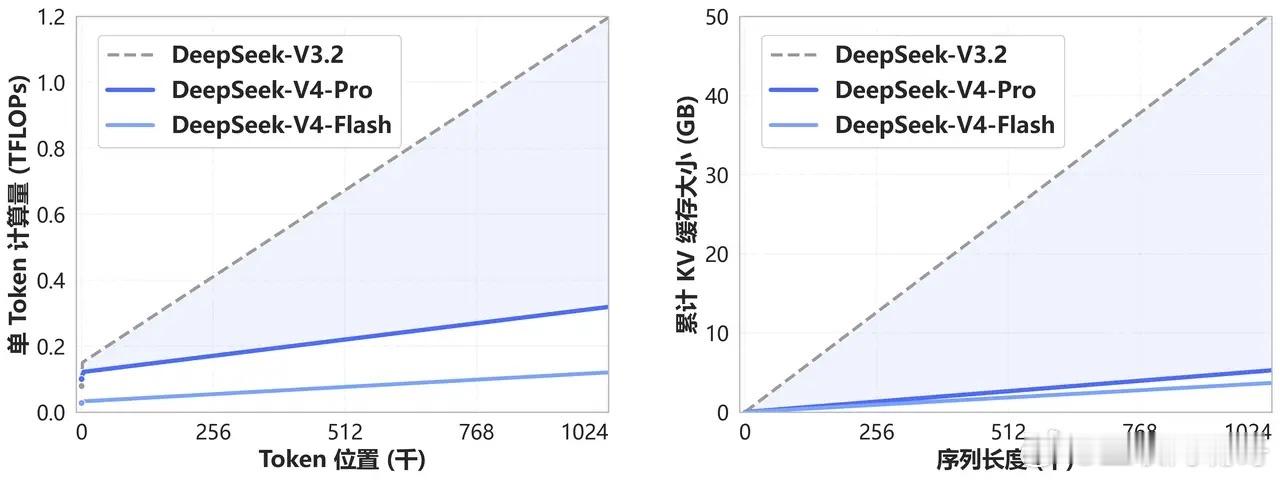
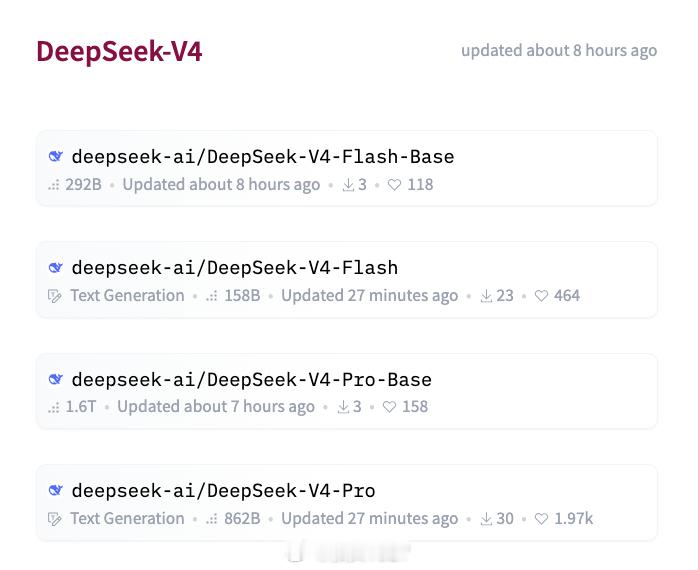
V4一共两个版本,Flash和Pro,都是开源。最直观的进步是上下文窗口达到100万token。你甩一整部《三体》三部曲进去,它都能一口气读完并回答你的问题。或者更实际的场景:直接把一整个代码仓库扔进去,不用再费劲分段粘贴。
但真正的亮点不是这个。
DeepSeek V4 Flash的定价是每处理100万个输入token收费0.14美元,输出0.28美元。对比一下,GPT-5.4 Nano同样100万输入token要0.20美元,输出则跳到1.25美元,是DeepSeek的四倍多。Claude Haiku 4.5更夸张,输出端每百万token收5美元,差了将近18倍。Pro级别的差距同样残酷:V4 Pro输出每百万token 3.48美元,而GPT-5.5要30美元,Gemini 3.1 Pro要12美元。
如果这些数字让你觉得抽象,换个算法:用V4 Pro生成一万字的文章,模型厂商收你的钱大概是人民币两毛钱出头。同样的活交给GPT-5.5,要两块钱上下。一件事情重复做一千次,差价就是一千八百块。对于把AI接口嵌进产品的开发者来说,这个差距是按月计算服务器账单时能直接决定盈亏的那根线。
这么便宜,是不是因为模型本身不行?
DeepSeek在技术报告里罕见地坦白了差距:V4 Pro Max版本在标准推理基准上超过了GPT-5.2和Gemini 3.0 Pro,但落后于GPT-5.4和Gemini 3.1 Pro,大概差了3到6个月的身位。被拿来比较的已经是各家最新最强的模型。它在性能上不是第一名,但已经坐进了第一排,而价格只有别人的十分之一甚至更低。
这个价格是怎么办到的?
核心在架构。V4用了混合专家模型,简称MoE。传统的超大模型在处理每个问题时,整个模型的全部参数都会被激活一次,像一家医院每来一个病人都召集全科会诊。MoE的做法不同:总参数可能有上万亿,但每次只唤醒其中一小部分专家模块。你看感冒就只挂呼吸科,骨科眼科心外科该休息照常休息。激活的参数少了,算力消耗断崖式下降。
推理成本低,给用户的定价就可以低。一个由工程优化驱动的商业飞轮就此转起来:架构省算力→算力省电→电省成本→成本省出定价空间。
还有一个隐藏但致命的环节:开源。
V4用的是MIT许可证,代码和模型权重全部公开。这意味着任何有服务器的团队都可以自己部署,不再需要每次调用都向DeepSeek付费。当然,这不等于完全免费。你的GPU在运转,电表在转,机房在散热,钞票还是在流动。但跟按token付费比起来,这是自己种菜和天天下馆子的区别。流水可以控制在自己手里。
回看时间线,从R1推理模型震惊硅谷到现在V4开源发布,只有一年多。R1当年引起的震荡远不只是技术讨论。2025年1月27日,纳斯达克期货暴跌,英伟达单日市值蒸发近6000亿美元。当时市场恐慌的逻辑是:如果一家公司能用少得多的芯片训练出有竞争力的模型,那之前市场对高端芯片需求的预期是不是吹过头了?
V4没有重复那天的戏剧性。但它用一组定价数字把同一个逻辑往前推进了一步:这场竞争已不再仅仅是谁的模型更聪明,更是谁能把聪明的价格打到让对手无法跟牌的地步。
此刻,全球几个最大的AI厂商面对的是一个微妙处境。性能上,他们可能还领先半个身位。但成本战线上,那个从杭州出发的对手,已经把价格压到了他们定价体系的十分之一区间。随着权重完全开放,本地部署V4 Flash的技术门槛已经大幅降低。
当模型的访问价格降到这个量级,它开始变成水电一样的基础设施。手机应用、企业工具、教育软件的后台都有理由接入这类模型。便宜的推理成本正在渗入所有数字服务的底层,而不是停留在科技新闻的标题里。
而账单那头的差价,正在决定谁家的接口会被更多开发者选为默认选项。
~~~~~~
图为DeepSeek iPhone 应用程序
信源:Gil, Bruce. "DeepSeek’s Newest Models Take on Silicon Valley at a Fraction of the Cost." Gizmodo, 24 Apr. 2026