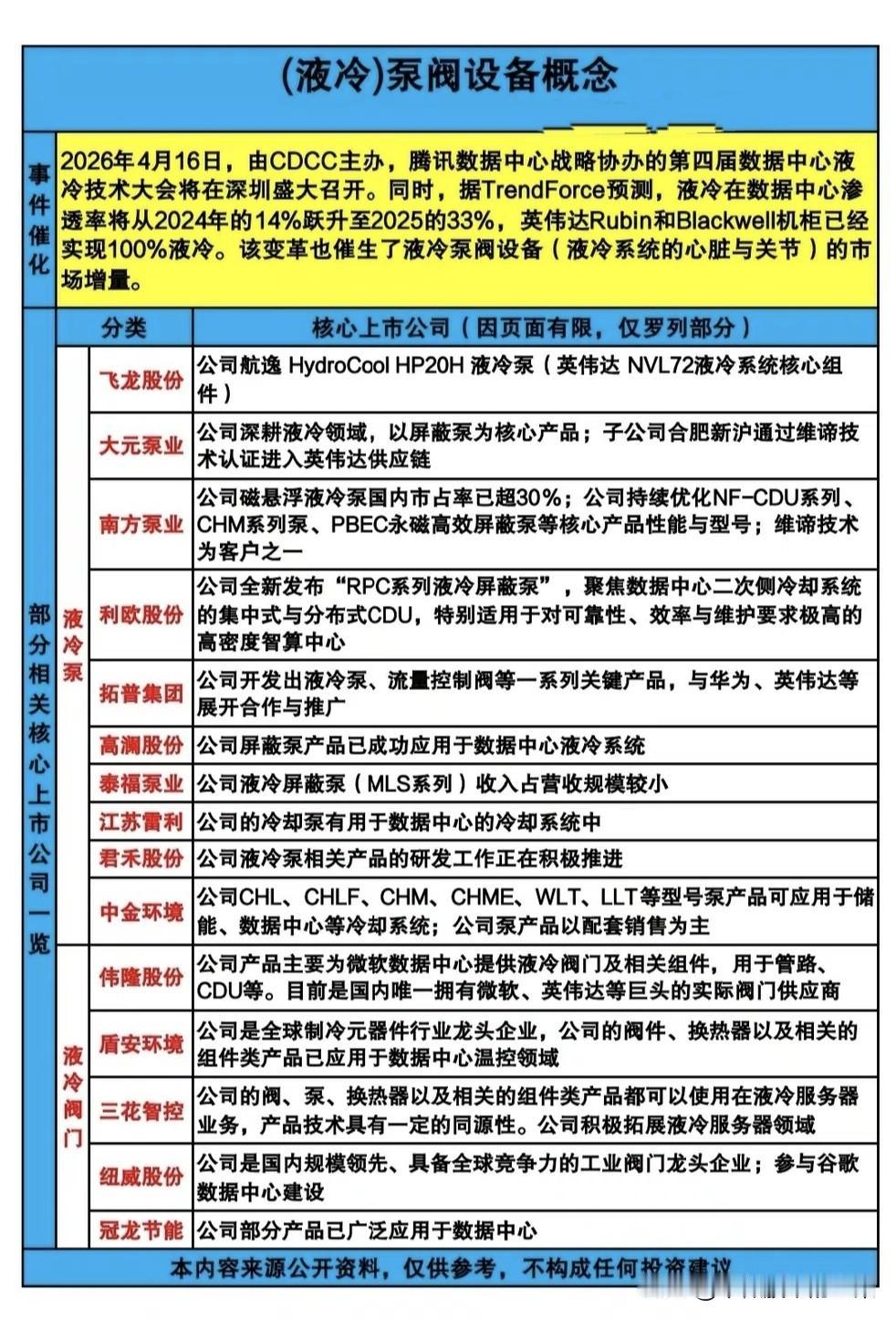
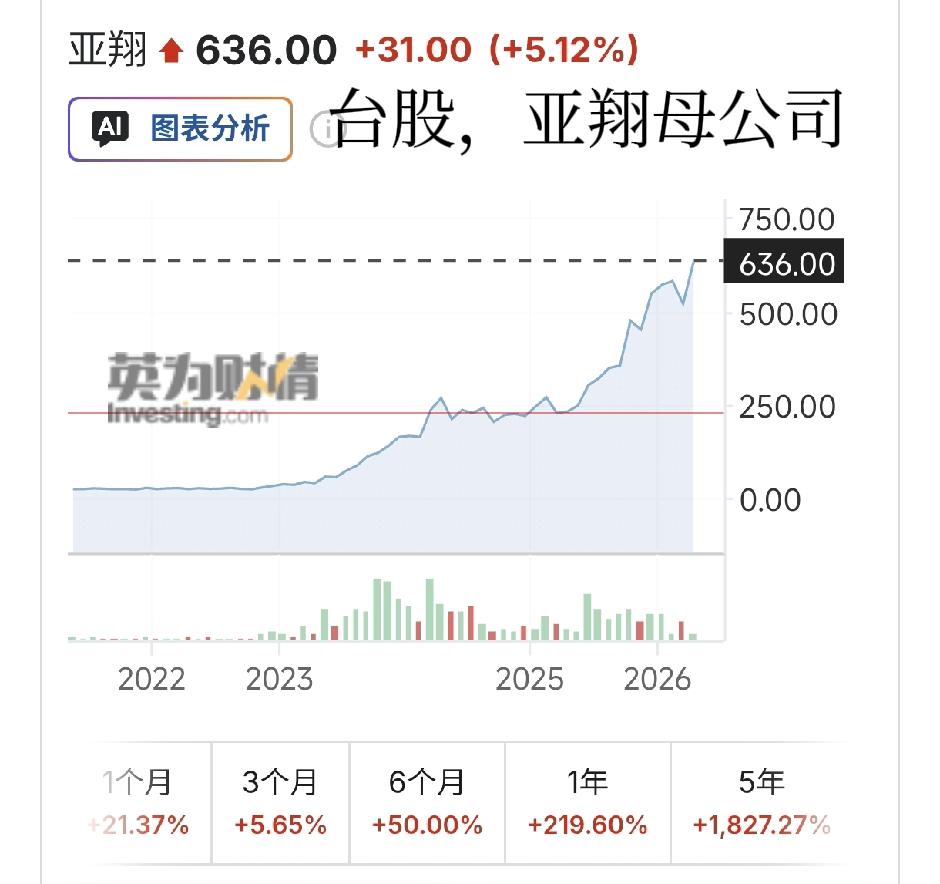
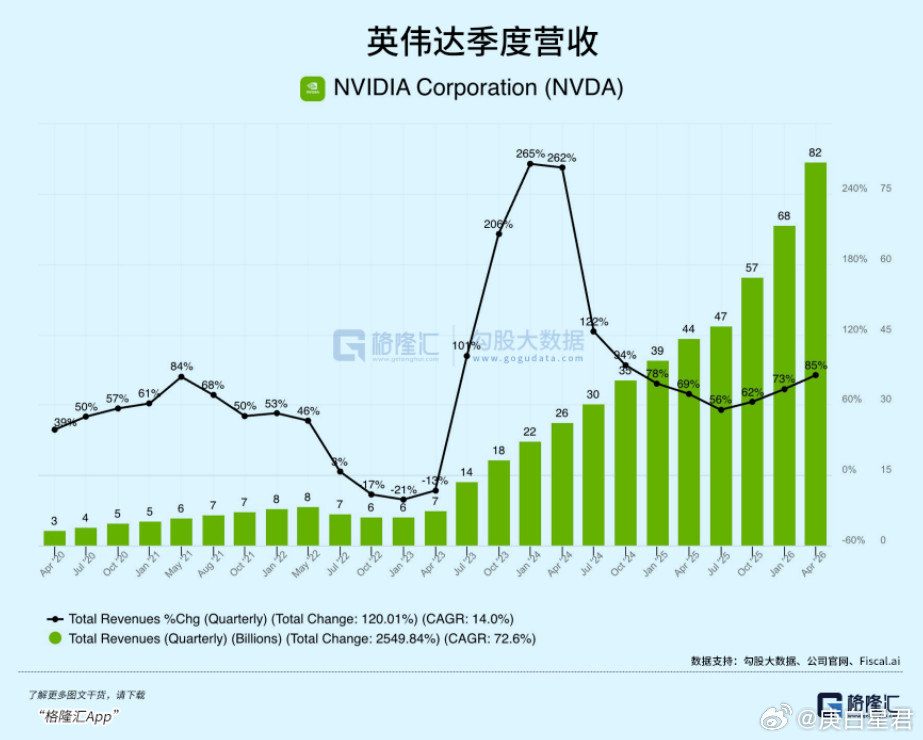
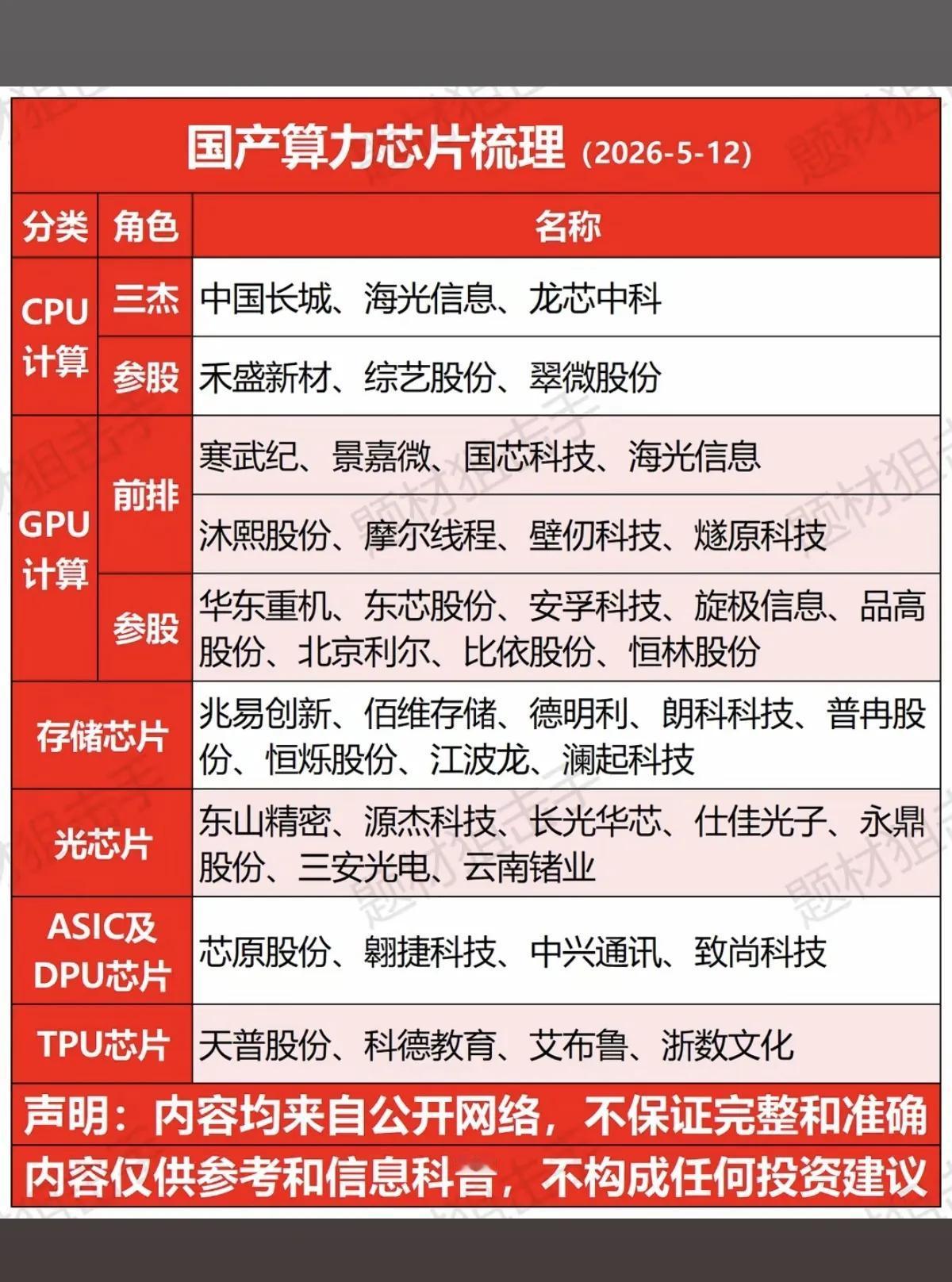
标签: GPU


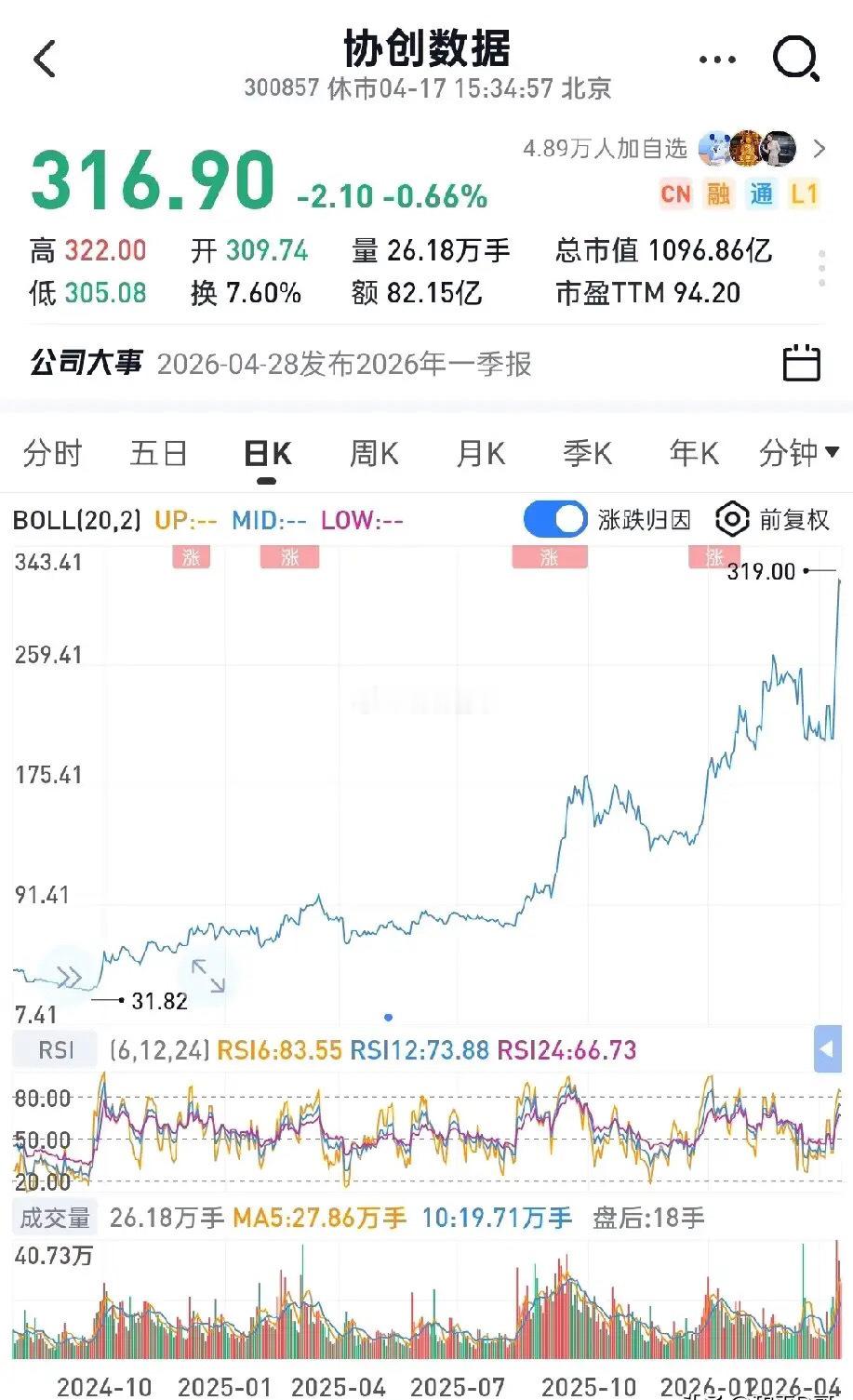
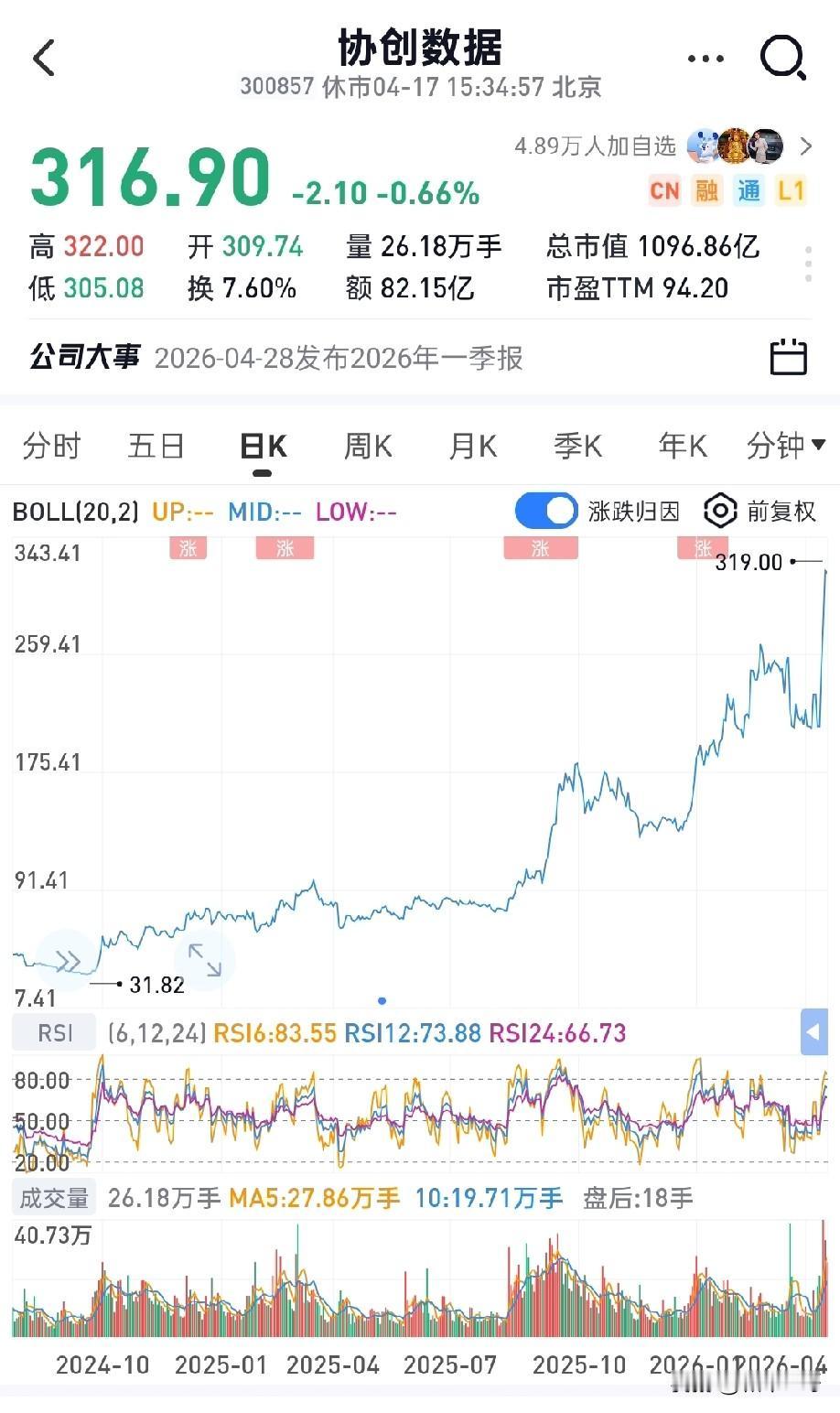
单台售价780万美元(约5000万人民币)!英伟达下一代Rubin(VR200)
单台售价780万美元(约5000万人民币)!英伟达下一代Rubin(VR200)AI机柜彻底炸场了。摩根士丹利最新拆解显示,这机器由130万个零部件打造,性能较上代暴增10倍。最关键的信号:AI利润正在从GPU向外围硬件大规模溢出!GPU占比从65%降至51%,内存、PCB、MLCC等细分赛道迎来史诗级价值重估:-内存(HBM4):占比26%,暴涨435%-高端PCB:涨幅233%-高端MLCC:涨幅182%-ABF载板:涨幅82%中国供应链已成绝对主力,核心受益标的一个不落:🔹高端PCB:胜宏科技(300476)、沪电股份(002463)、鹏鼎控股(港股)、生益科技(600183)🔹HBM/内存:澜起科技(688008)、香农芯创(300475)🔹ABF载板:兴森科技(002436)、深南电路(002916)🔹MLCC:风华高科(000636)🔹液冷/电源/连接器:高澜股份、英维克、中航光电、得润电子AI竞争已进入全链条博弈时代,国产硬科技这次真的站上C位了。注:以上信息整理自公开研报,不构成投资建议


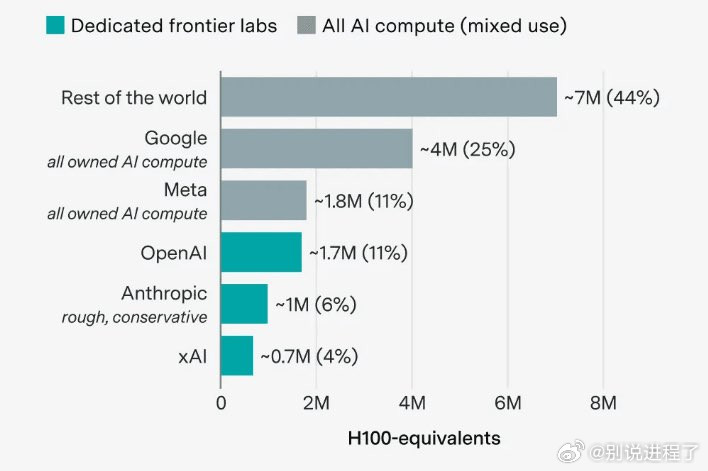
大型人工智能公司占据全球计算能力的一半……谷歌以25%的市场份额位居榜首1/少
大型人工智能公司占据全球计算能力的一半……谷歌以25%的市场份额位居榜首1/少数几家前沿科技公司在全球人工智能计算市场的主导地位正在迅速增强。尽管它们目前的市场份额尚未达到一半,但它们仍在积极扩张。2/根据EpochAI的一份报告,到2025年底,谷歌将以400万个H100GPU占据全球25%的计算能力,位居榜首。然而,报告显示,分配给Gemini项目的开发比例不足一半。3/OpenAI以170万个GPU位列第三,而Meta和微软也在积极获取大规模的计算资源。中国公司DeepSearch也正通过外部投资和自建设施迅速追赶。4/如果这种计算资源集中化的趋势持续下去,未来的成败将取决于能否创造可观的利润和经济效益。由于物理限制和天文数字般的成本,可持续性已成为一项关键挑战。

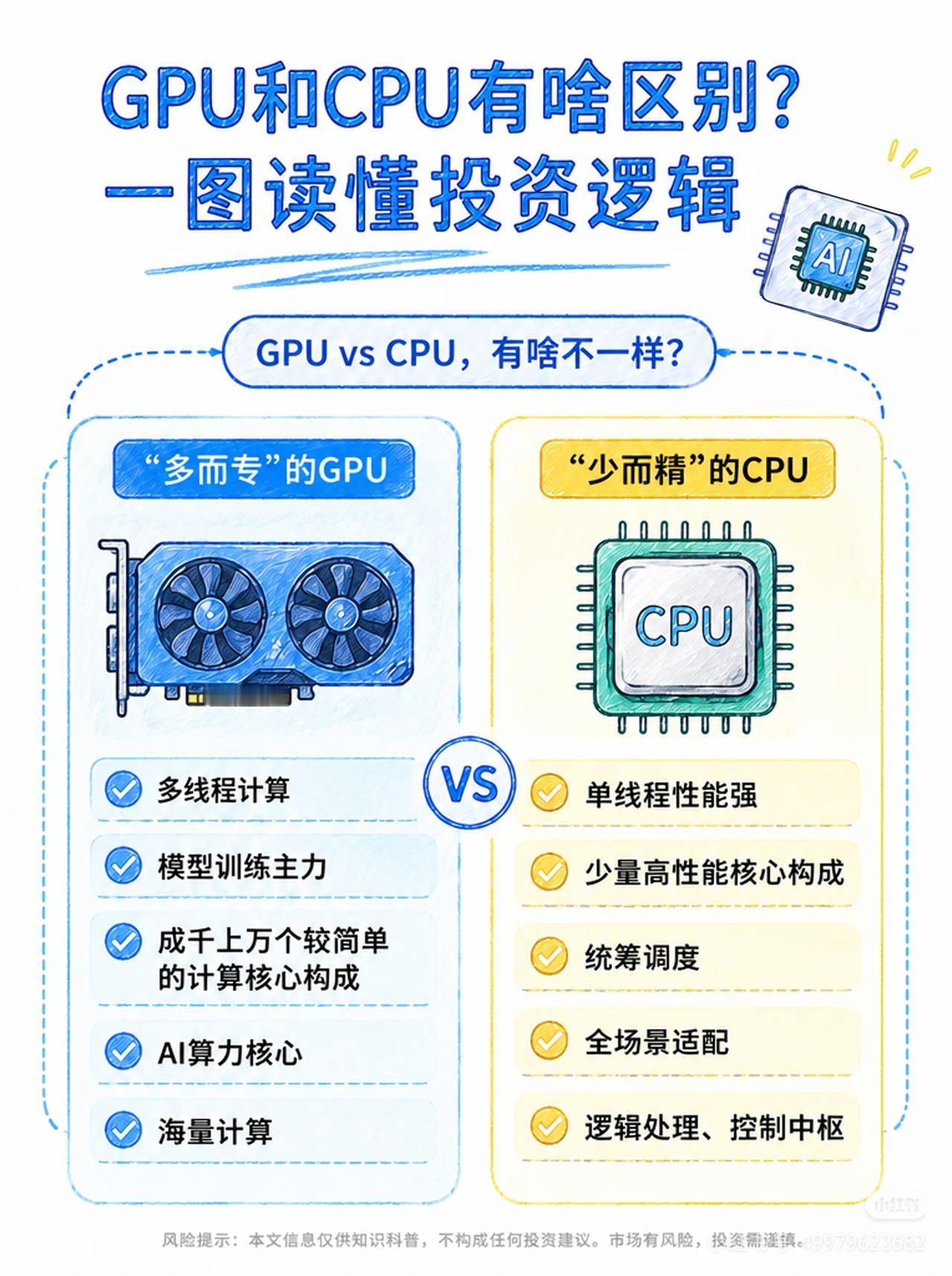



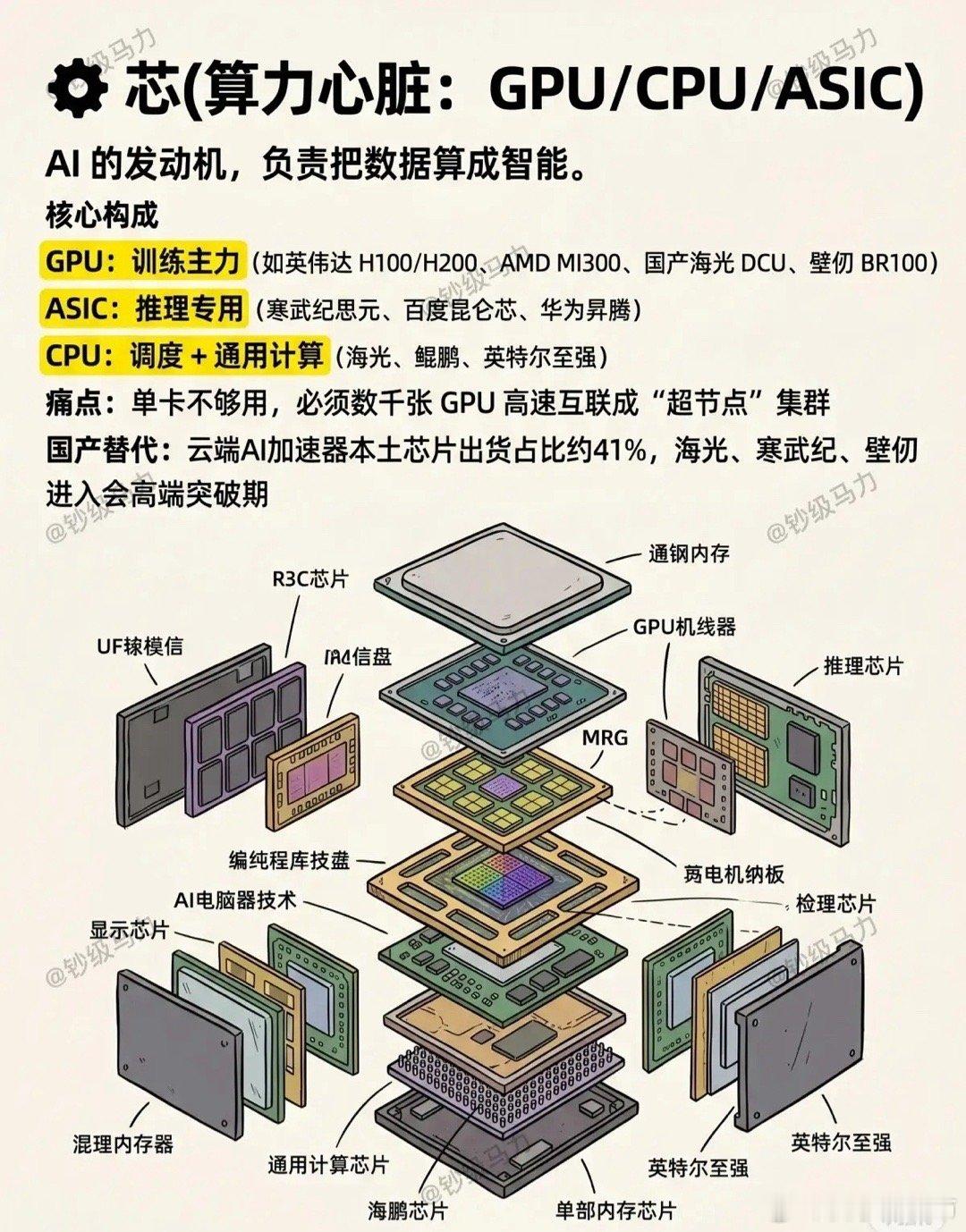



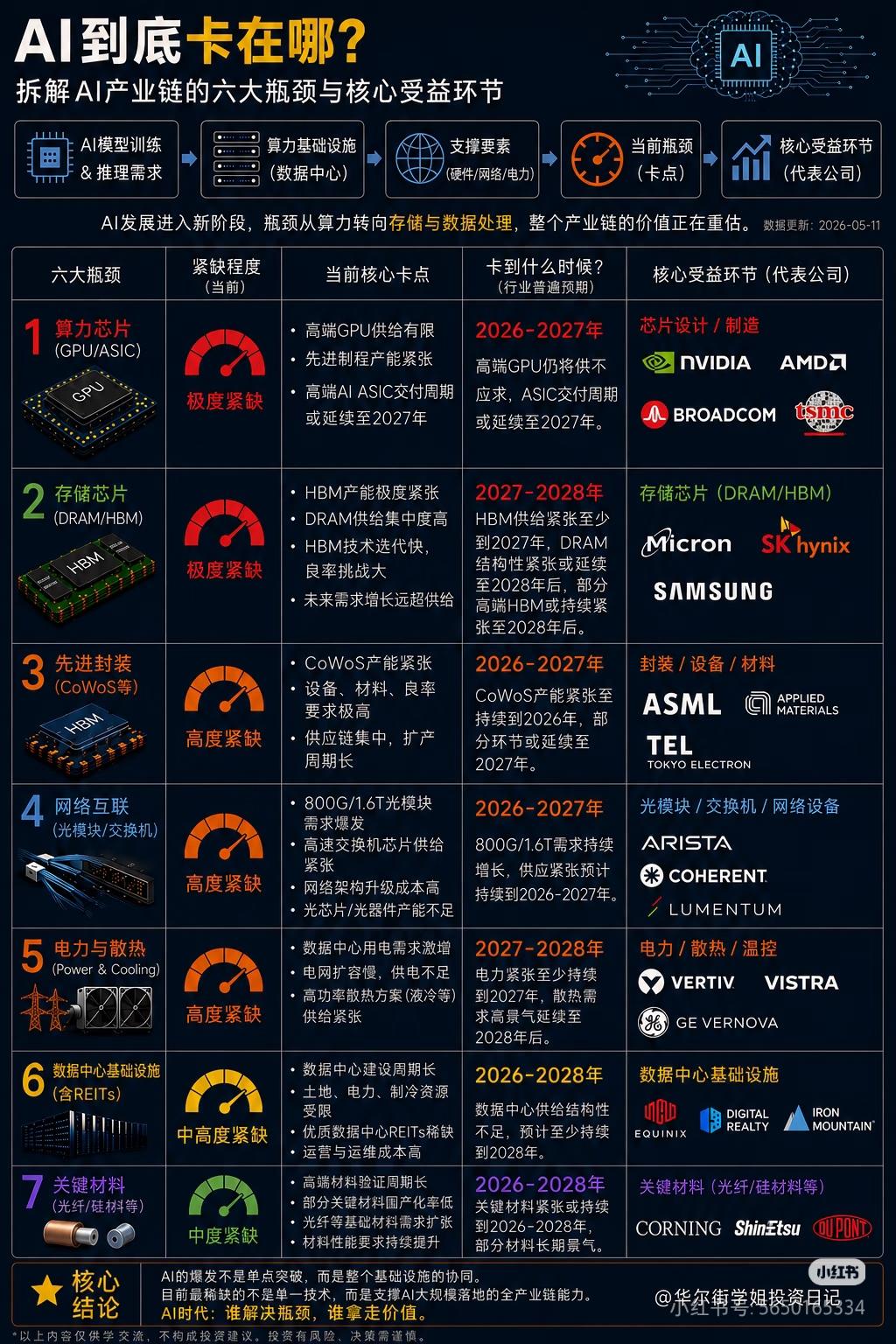
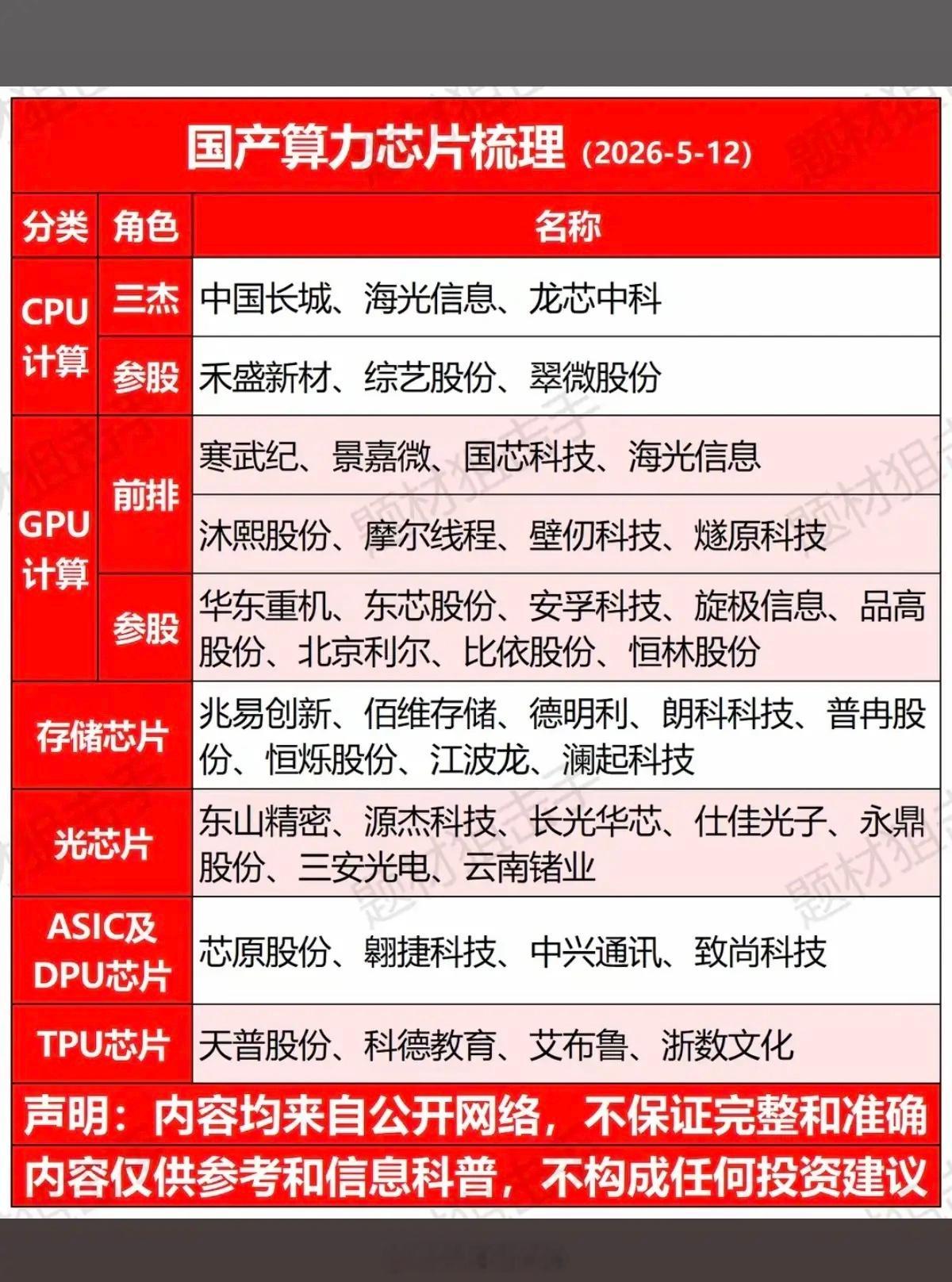
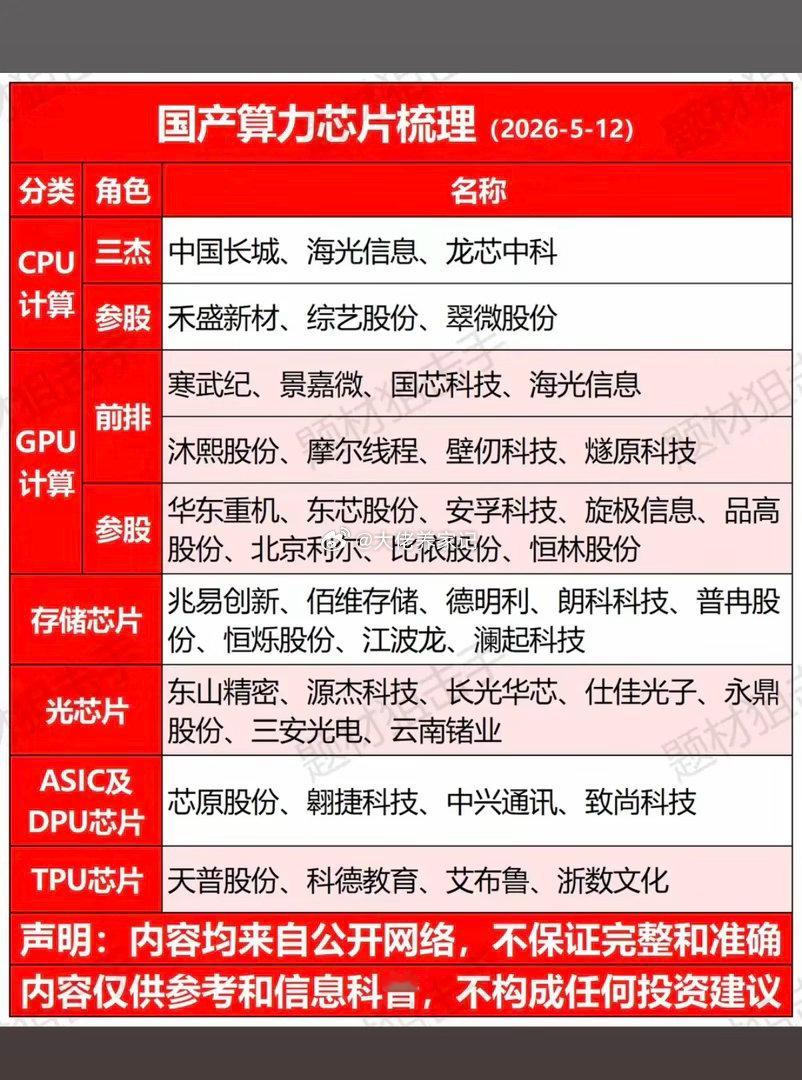
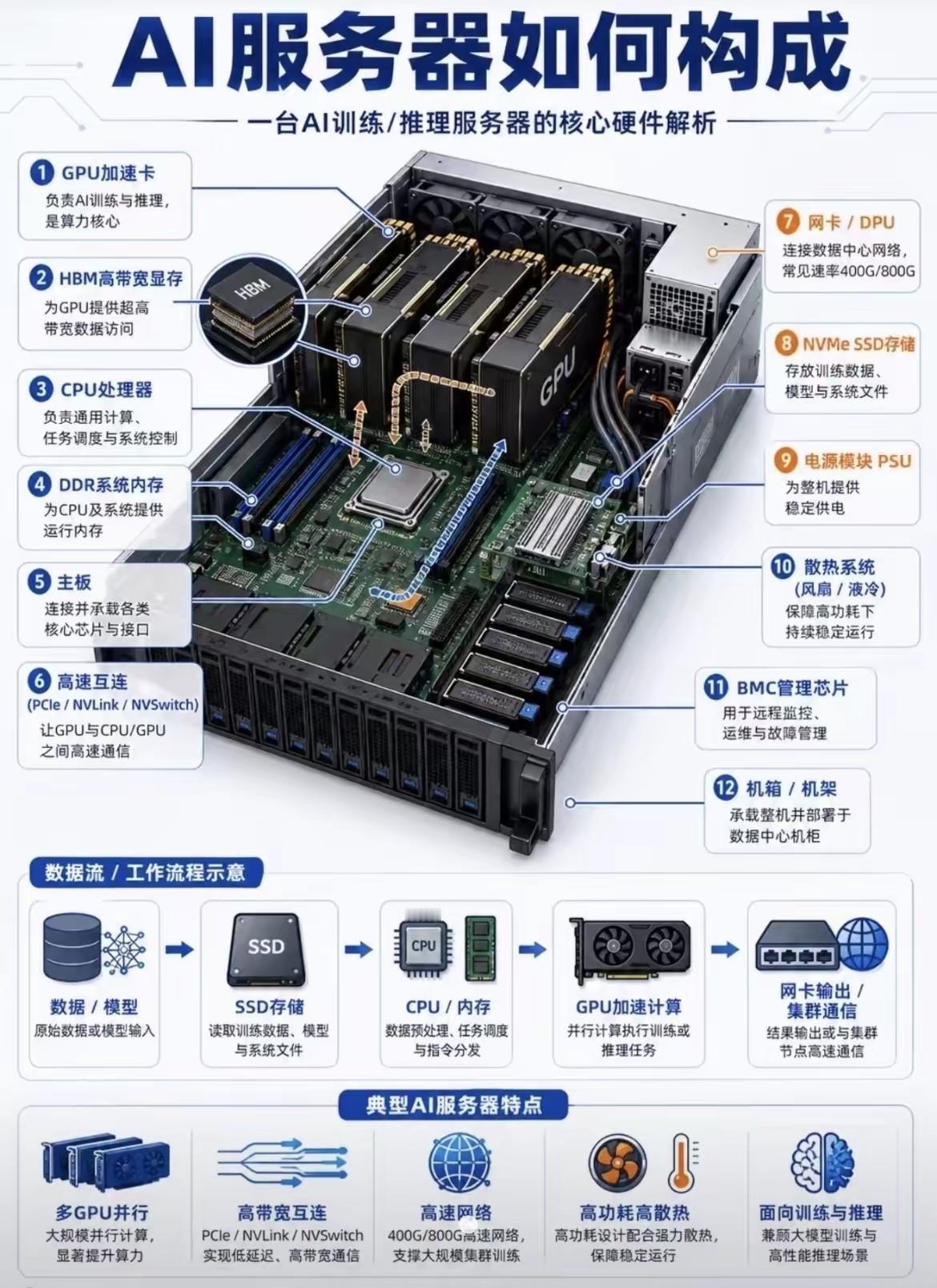
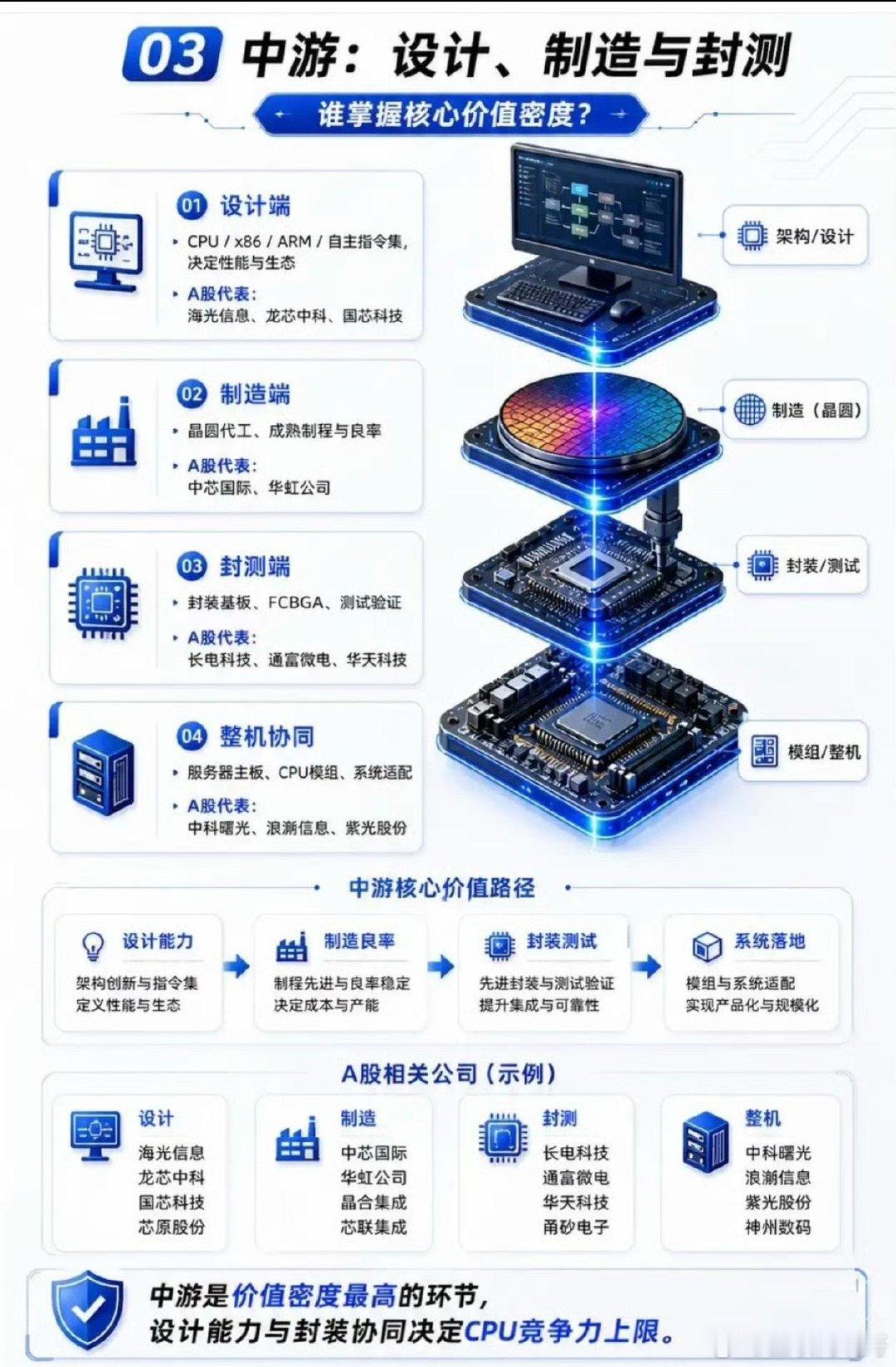
人工智能三大支柱(算力芯片、通信网络、工业体系)的构成、作用和价值一、第一支
人工智能三大支柱(算力芯片、通信网络、工业体系)的构成、作用和价值一、第一支柱:算力芯片,AI的“发动机”。核心硬件通用GPU:英伟达A100/H100、AMDMI250,大模型训练主力,强并行计算。AI专用芯片(ASIC/NPU/DCU):华为昇腾、寒武纪、壁仞、海光,针对深度学习定制,能效更高、成本更低。FPGA:可编程,适合边缘低延迟推理(工业、自动驾驶)。存算一体/光计算芯片:前沿方向,解决“存储-计算”数据搬运瓶颈。核心作用提供原始算力:支撑大模型训练(如GPT-4需数万GPU)、推理(每天千亿次调用)。定义能效上限:决定AI能跑多快、多大模型、功耗多少(直接影响电费与成本)。构建算力集群:通过NVLink/InfiniBand互联,组成“超级大脑”,支撑分布式训练。一句话价值没有算力芯片,AI就是纸上谈兵;芯片的性能与供给,决定国家AI竞争力的底线。目前来看,美国在算力算法和芯片方面,略占优势,中国在迎头赶上。二、第二支柱:通信网络,AI的“血管”。构成(三层网络)数据中心内网(高速互联):InfiniBand、NVLink、400G/800G光模块,低延迟、高带宽,GPU间通信。骨干网/算力网络:5G和未来的6G基站网络、光纤、卫星互联网,连接智算中心、边缘节点、用户终端。边缘接入网:工业以太网、Wi-Fi7、物联网(IoT),设备端数据采集与实时控制。核心作用数据高速流通:海量训练数据、模型参数、推理请求在云-边-端实时传输。支撑云边端协同:大模型在云端训练,边缘实时推理(自动驾驶、工业质检),终端交互。保障低延迟高可靠:自动驾驶、远程医疗、工业控制等场景,毫秒级延迟是安全底线。目前的5G技术和未来的6G技术,是人工智能的支撑性基础技术。5G的研发和应用,中国走在世界的前列。6G的研发,目前中国又走在前列。一句话价值网络不通,算力无用;网络带宽与延迟,直接决定AI应用的可用性与体验。三、第三支柱:工业体系,AI的“骨骼与土壤”。构成(四大产业链)半导体制造:晶圆代工(台积电、中芯国际等)、光刻/刻蚀/沉积设备、先进封装(Chiplet),决定芯片能否量产。算力基建(智算中心AIDC):高密度服务器、液冷散热、高压供电、储能/绿电,大规模算力交付。算力的运算,需要消耗相应的电力,电力决定算力。得益于风电、光伏发电、水电和核电的大发展,从近3年发电量来看,中国的年发电量几乎是美国、印度、俄罗斯、日本、德国、法国和英国的总和。液冷散热、特高压供电、储能/绿电,还有在人形机器人中将电能转化为精准机械运动,也是中国的强项。整机与智能制造:AI服务器、工业机器人、智能产线,支撑算力硬件规模化生产与AI落地。软件与生态:操作系统、AI框架(TensorFlow/PyTorch)、编译器、行业解决方案,让硬件可用、模型可落地。核心作用硬件规模化供给:稳定、低成本生产GPU/NPU、服务器、光模块,支撑AI算力爆发式需求。工程化落地能力:把算法模型变成可量产、可运维、可迭代的产品(如工业质检、自动驾驶、无人机、无人艇、机器狗、战狼等)。得益于中国完整的工业体系和供应链,相对美国的产业空心化来说,中国人工智能产品的工程化、产品化、市场化和迭代能力都相对要好些。产业链安全自主:避免“卡脖子”,保障芯片、设备、软件的自主可控,支撑长期发展。一句话价值工业体系不强,AI只能“空中楼阁”;完整的产业链,是AI从实验室走向产业的根本保障。四、三者关系总结算力芯片是动力源,提供计算能力;通信网络是传输纽带,连接算力、数据与场景;工业体系是制造与工程底座,保障硬件量产与应用落地。三者缺一不可,共同构成AI产业的“硬支撑”,决定一个国家AI发展的上限与安全。

















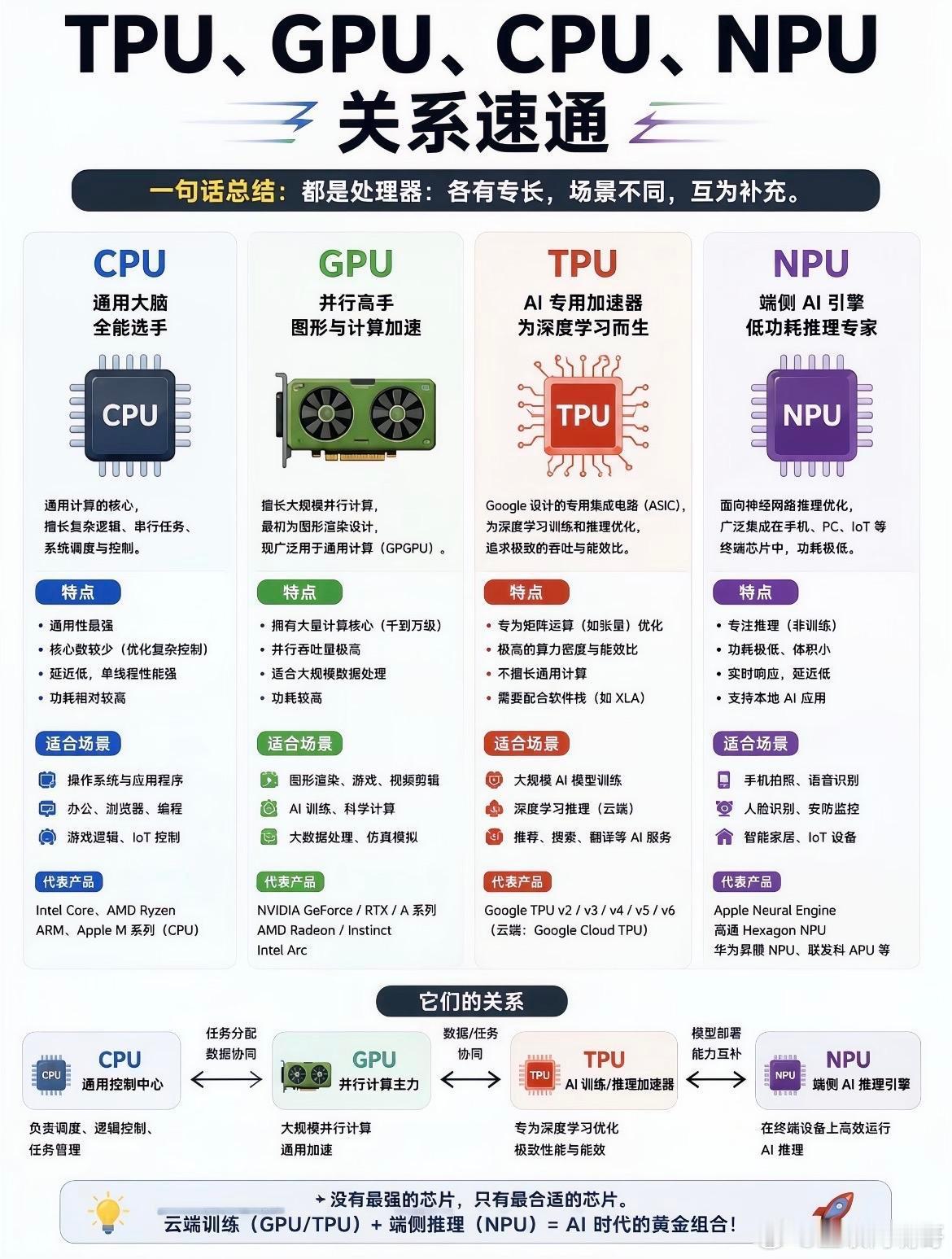
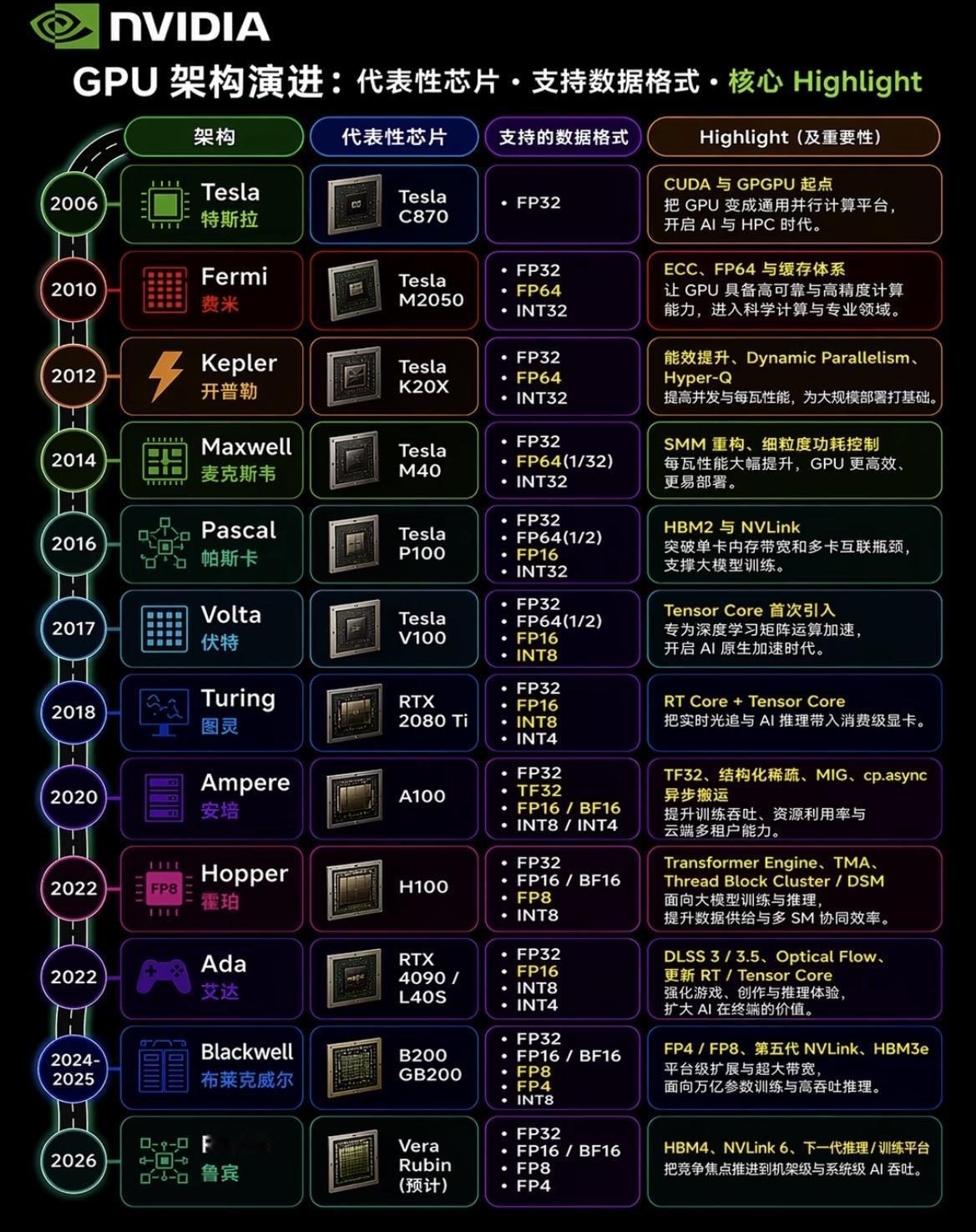
一文速览CPUGPUNPUTPU
一文速览CPUGPUNPUTPU





看罢此图,深感老马目光之毒辣同行还在卷模型参数,他已洞悉天机,开始圈地建“算
看罢此图,深感老马目光之毒辣同行还在卷模型参数,他已洞悉天机,开始圈地建“算力帝国”疯狂囤积55万GPU,不仅为Grok筑基,更化身“算力包租公”,把余力租给Cursor们这哪是单纯做AI,分明是在抢占AI时代的“石油”与“电力”,商业闭环既成,规则由其定义




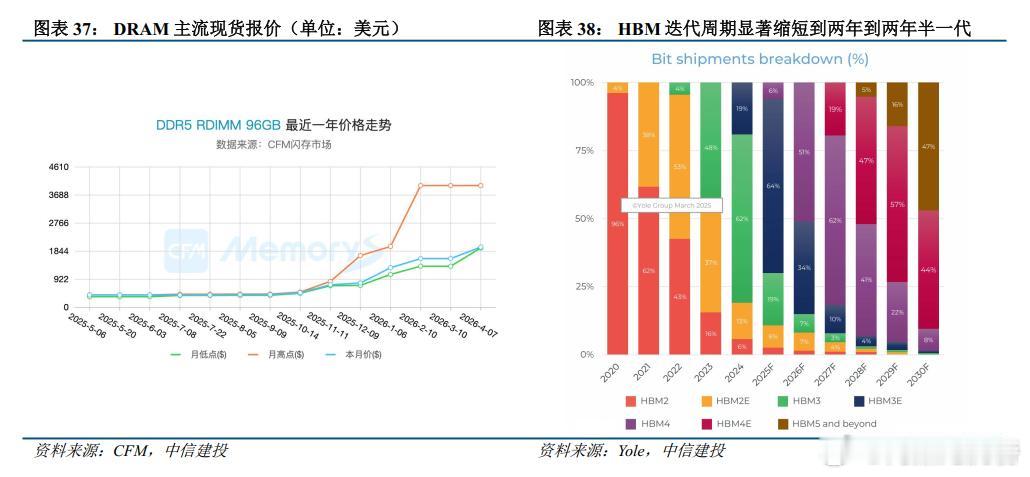
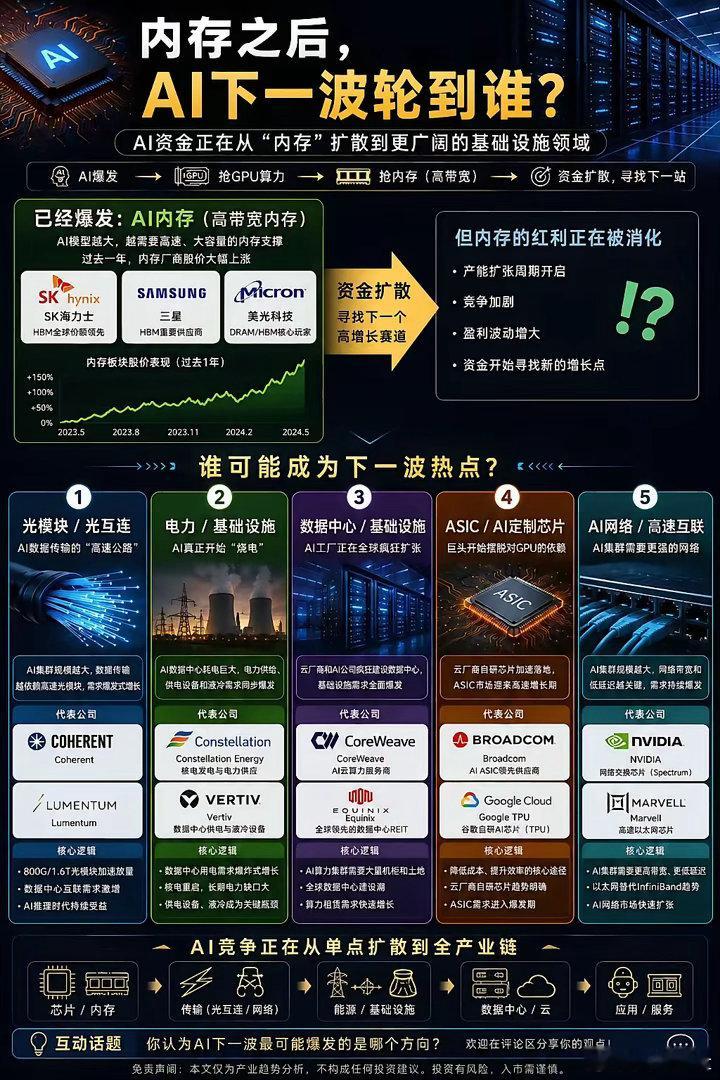
美光这话一放出来,存储芯片的味道就变了以前大家总盯着算力,觉得GPU才是命根子,
美光这话一放出来,存储芯片的味道就变了以前大家总盯着算力,觉得GPU才是命根子,现在看,真正卡脖子的反倒是“装记忆的地方”不够用5月7日,美光高管直接说了,AI一旦跑起来,数据越堆越多,存储根本跟不上最扎心的是,这不是一两天的热闹大模型还在长,上下文越拉越长,云厂商也不敢停手,钱继续往里砸晶圆厂那边再怎么赶工,产能还是像挤牙膏,远远不够说白了,AI最先把谁带飞,未必是算力,可能是存储HBM、SSD这些以前不算最抢眼的东西,现在反而成了香饽饽这行情要是真按这个路子走下去,存储芯片还真不像过去那样一波涨完就歇问题来了,这次到底是新周期,还是又一轮高开高走的热闹场面



高通发布骁龙6Gen5和骁龙4Gen5:骁龙6Gen5:4*2.6G
高通发布骁龙6Gen5和骁龙4Gen5:骁龙6Gen5:4*2.6GHzP-Core+4*2.0GHzE-Core,台积电4nm,相比前代,功耗降低8%,GPU提升20%,支持200MP、100X变焦,支持王者荣耀120FPS,WiFi7,荣耀和REDMI首批终端。骁龙4Gen5:2*2.4GHzP-Core+6*2.1GHzE-Core,台积电4nm,相比前代,功耗降低10%,GPU提升77%。支持90FPS游戏,OPPO、realme、REDMI首批终端。







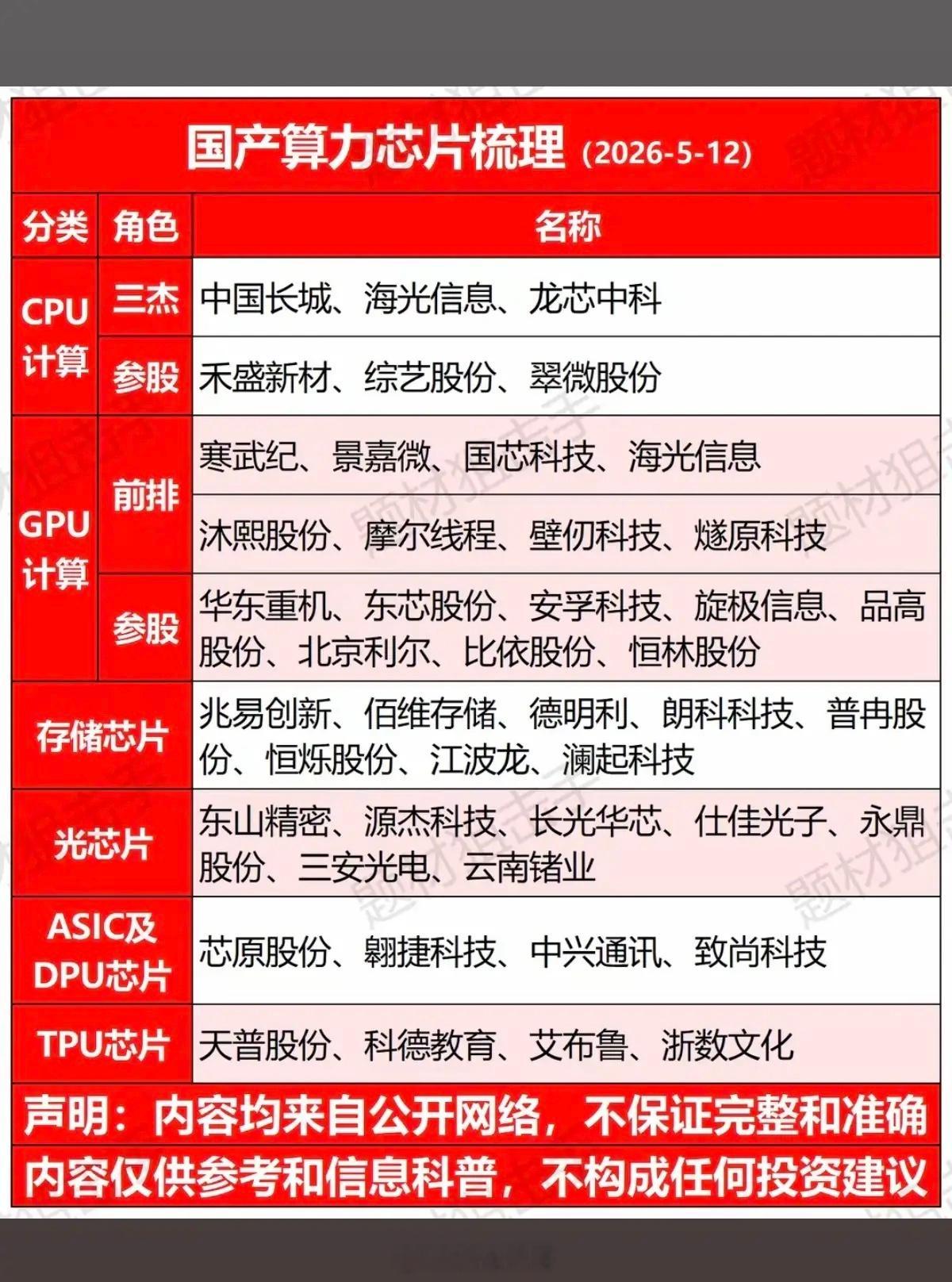
人工智能三大支柱(算力芯片、通信网络、工业体系)的构成、作用和价值一、第一支
人工智能三大支柱(算力芯片、通信网络、工业体系)的构成、作用和价值一、第一支柱:算力芯片,AI的“发动机”。核心硬件通用GPU:英伟达A100/H100、AMDMI250,大模型训练主力,强并行计算。AI专用芯片(ASIC/NPU/DCU):华为昇腾、寒武纪、壁仞、海光,针对深度学习定制,能效更高、成本更低。FPGA:可编程,适合边缘低延迟推理(工业、自动驾驶)。存算一体/光计算芯片:前沿方向,解决“存储-计算”数据搬运瓶颈。核心作用提供原始算力:支撑大模型训练(如GPT-4需数万GPU)、推理(每天千亿次调用)。定义能效上限:决定AI能跑多快、多大模型、功耗多少(直接影响电费与成本)。构建算力集群:通过NVLink/InfiniBand互联,组成“超级大脑”,支撑分布式训练。一句话价值没有算力芯片,AI就是纸上谈兵;芯片的性能与供给,决定国家AI竞争力的底线。目前来看,美国在算力算法和芯片方面,略占优势,中国在迎头赶上。二、第二支柱:通信网络,AI的“血管”。构成(三层网络)数据中心内网(高速互联):InfiniBand、NVLink、400G/800G光模块,低延迟、高带宽,GPU间通信。骨干网/算力网络:5G和未来的6G基站网络、光纤、卫星互联网,连接智算中心、边缘节点、用户终端。边缘接入网:工业以太网、Wi-Fi7、物联网(IoT),设备端数据采集与实时控制。核心作用数据高速流通:海量训练数据、模型参数、推理请求在云-边-端实时传输。支撑云边端协同:大模型在云端训练,边缘实时推理(自动驾驶、工业质检),终端交互。保障低延迟高可靠:自动驾驶、远程医疗、工业控制等场景,毫秒级延迟是安全底线。目前的5G技术和未来的6G技术,是人工智能的支撑性基础技术。5G的研发和应用,中国走在世界的前列。6G的研发,目前中国又走在前列。一句话价值网络不通,算力无用;网络带宽与延迟,直接决定AI应用的可用性与体验。三、第三支柱:工业体系,AI的“骨骼与土壤”。构成(四大产业链)半导体制造:晶圆代工(台积电、中芯国际等)、光刻/刻蚀/沉积设备、先进封装(Chiplet),决定芯片能否量产。算力基建(智算中心AIDC):高密度服务器、液冷散热、高压供电、储能/绿电,大规模算力交付。算力的运算,需要消耗相应的电力,电力决定算力。得益于风电、光伏发电、水电和核电的大发展,从近3年发电量来看,中国的年发电量几乎是美国、印度、俄罗斯、日本、德国、法国和英国的总和。液冷散热、特高压供电、储能/绿电,还有在人形机器人中将电能转化为精准机械运动,也是中国的强项。整机与智能制造:AI服务器、工业机器人、智能产线,支撑算力硬件规模化生产与AI落地。软件与生态:操作系统、AI框架(TensorFlow/PyTorch)、编译器、行业解决方案,让硬件可用、模型可落地。核心作用硬件规模化供给:稳定、低成本生产GPU/NPU、服务器、光模块,支撑AI算力爆发式需求。工程化落地能力:把算法模型变成可量产、可运维、可迭代的产品(如工业质检、自动驾驶、无人机、无人艇、机器狗、战狼等)。得益于中国完整的工业体系和供应链,相对美国的产业空心化来说,中国人工智能产品的工程化、产品化、市场化和迭代能力都相对要好些。产业链安全自主:避免“卡脖子”,保障芯片、设备、软件的自主可控,支撑长期发展。一句话价值工业体系不强,AI只能“空中楼阁”;完整的产业链,是AI从实验室走向产业的根本保障。四、三者关系总结算力芯片是动力源,提供计算能力;通信网络是传输纽带,连接算力、数据与场景;工业体系是制造与工程底座,保障硬件量产与应用落地。三者缺一不可,共同构成AI产业的“硬支撑”,决定一个国家AI发展的上限与安全。



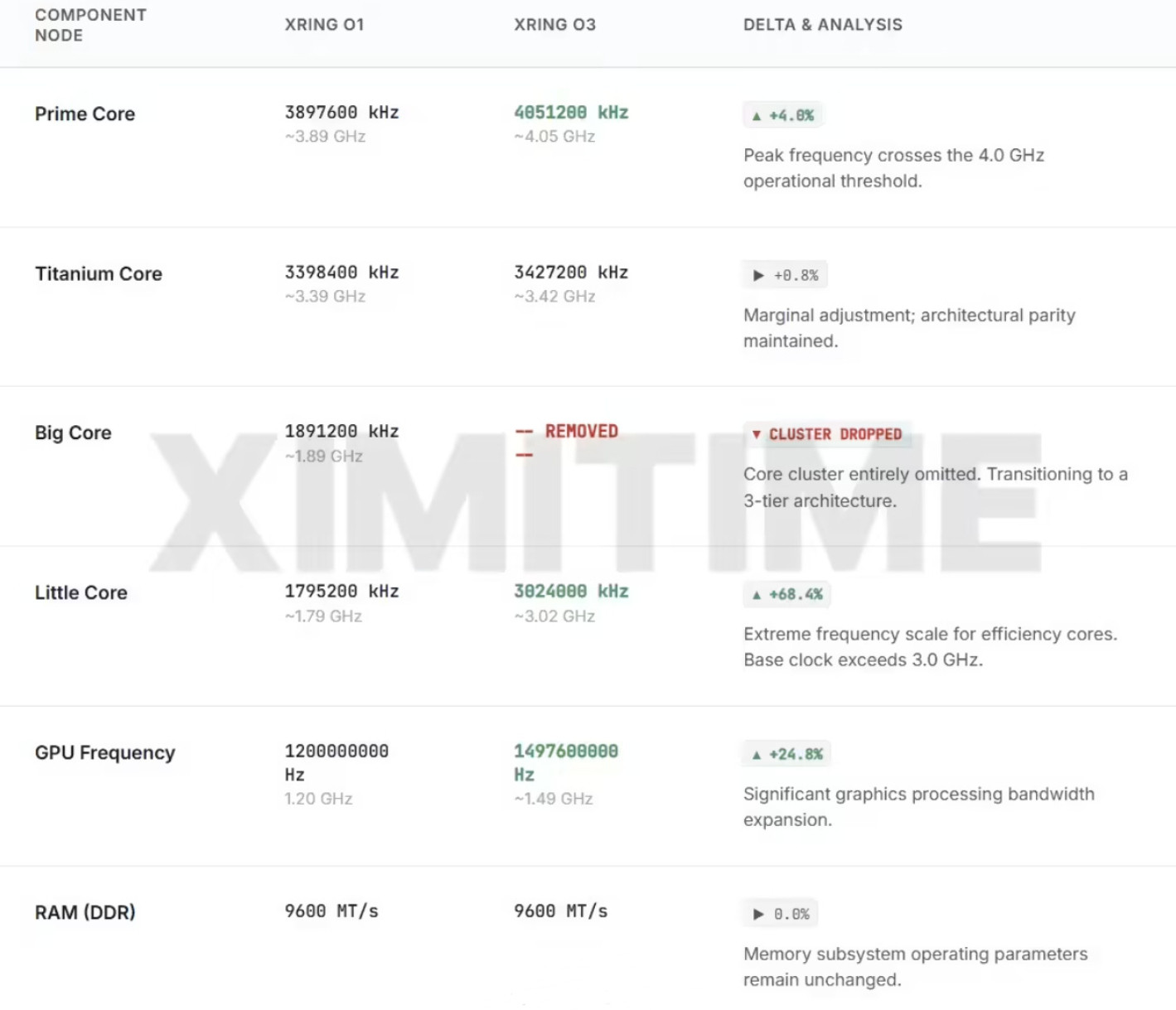





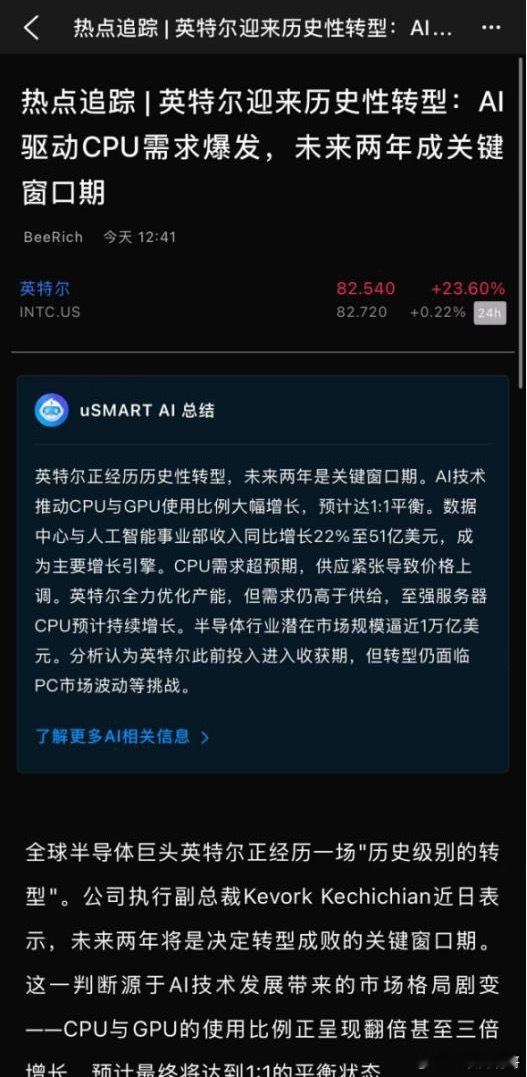
陈立武带英特尔杀疯了,CPU全域缺货陈立武上任一年多,英特尔这波是真的打出了翻
陈立武带英特尔杀疯了,CPU全域缺货陈立武上任一年多,英特尔这波是真的打出了翻身仗。Q1营收136亿美元,数据中心AI业务暴增22%到51亿,服务器CPU量价齐升。但更关键的不是这些数字,而是一个配比变化。英特尔CFO在财报会上亲口说的:AI服务器里,CPU和GPU的部署比例已经从1:8缩到了1:4。随着推理和Agent场景起量,这个比例还会往1:1走。翻译一下——GPU不变,CPU需求翻好几倍。结果就是供应炸了。至强CPU有几十亿颗级别的未满足订单,交付拉长到六个月。3月以来价格涨了10%-20%,消息说三季度还要再涨。用刚刚看到中信证券复盘研报的话说:以前都觉得AI全靠GPU,现在发现CPU这块短板不补上,万卡集群根本跑不顺。x86生态成熟、方案现成,拿过来就能用。这个窗口期里,国内x86路线的价值也在被重新审视。中国移动2026年国产服务器采购中,光一个批次就包含海光CPU服务器超400台。这类深耕x86赛道的厂商,已经站在了AI算力下半场的起跑线上。





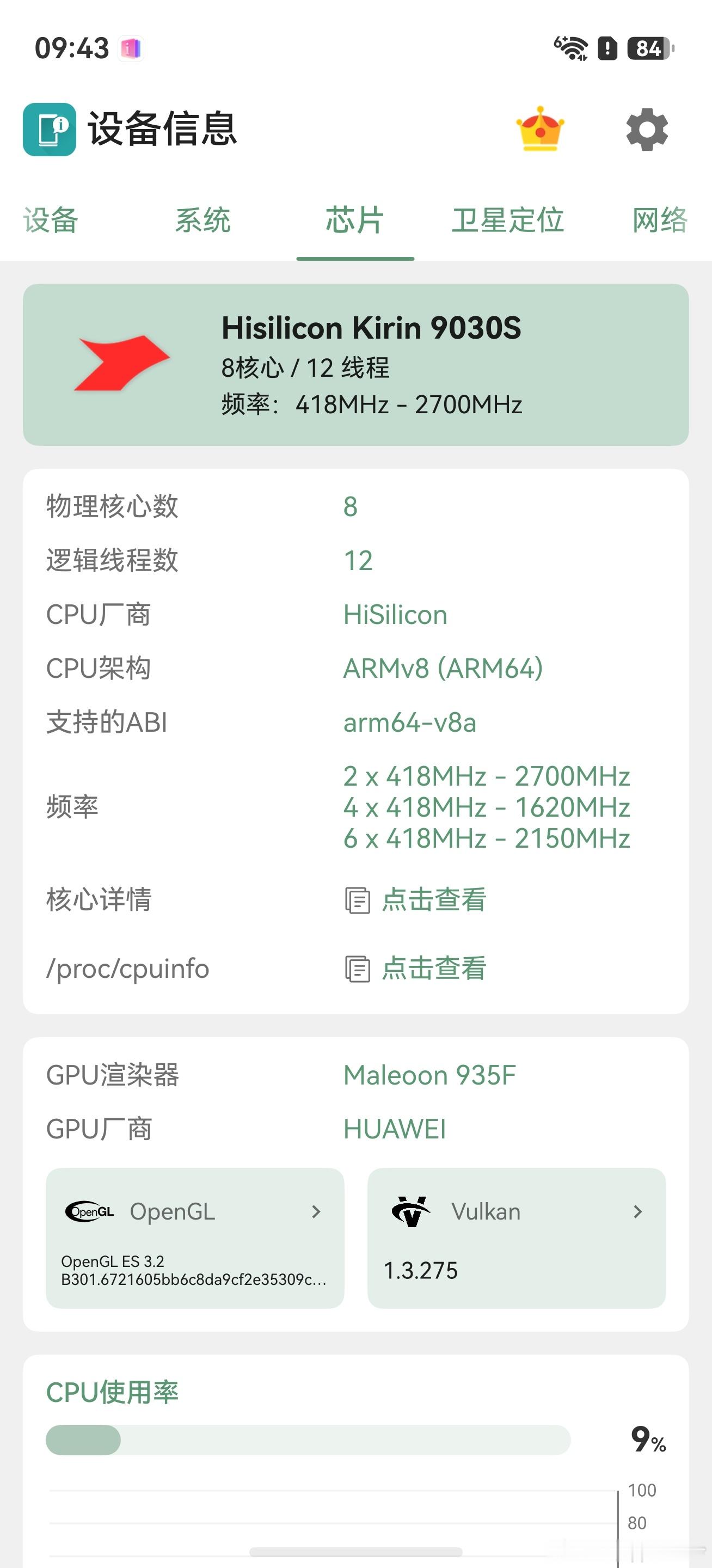


【英特尔发布第三代酷睿处理器】英特尔发布了代号为WildcatLake的第三代
【英特尔发布第三代酷睿处理器】英特尔发布了代号为WildcatLake的第三代英特尔酷睿移动处理器,其CPU、NPU和GPU架构与第三代英特尔酷睿Ultra处理器PantherLake一样,计算模块采用Intel18A制程节点。计算模块里面拥有2个P核和4个LPE核,内部整合NPU5和Xe3架构的GPU,GPU拥有两组Xe核心,支持7467MT/s的LPDDR5x和6400MT/s的DDR5内存,拥有4MB内存侧缓存。平台控制模块可提供6条PCIe4.0通道,两个雷电4接口,两个USB3.2和最多8个USB2.0接口,并集成Wi-Fi7和蓝牙6.0。该系列产品共包含六款型号,除一款为五核外,其余均为六核。五核的只配备了一个Xe3核心。所有处理器的基础功耗均为15W,最大功耗均为35W,具体规格可参考配图。4月16日起,搭载第三代英特尔酷睿处理器的消费级与商用产品将由OEM合作伙伴在今年内陆续推出,搭载第三代英特尔酷睿处理器的边缘计算系统将于2026年第二季度开始供货。