
一、模型核心定位
Qwen3.6-35B-A3B 是阿里云通义千问团队于 2026年4月15日 发布的最新开源大语言模型,其命名中的关键参数揭示了技术路线:
参数
含义
35B
总参数量 350 亿
A3B
激活参数量仅 30 亿(Active 3 Billion)
MoE
采用混合专家(Mixture of Experts)架构
这一设计理念明确指向 "稀疏但强大" 的技术路线——通过 MoE 架构在保持高性能的同时大幅降低推理成本,使其成为当前最具通用性的开源模型之一。
二、核心技术特性
1. 架构创新:稀疏激活的 MoE 设计
与传统稠密模型(Dense Model)不同,Qwen3.6-35B-A3B 采用 稀疏激活策略:
• 总参数:350 亿(存储完整模型能力)
• 激活参数:仅 30 亿(每次前向传播实际计算)
• 效率比:约 11.7:1 的压缩比
这意味着:
✓ 推理成本极低:每次推理仅需计算 3B 参数,而非 35B
✓ 部署门槛低:消费级 GPU(如 RTX 4090)即可流畅运行
✓ 响应速度快:低计算量带来更快的 token 生成速度
2. 双模式支持:思考与非思考
模型原生支持两种工作模式:
模式
适用场景
特点
思考模式
复杂推理、编程、数学
深度思考,质量优先
非思考模式
简单问答、日常对话
快速响应,效率优先
这种设计让开发者可以根据任务复杂度灵活选择,避免"杀鸡用牛刀"的资源浪费。
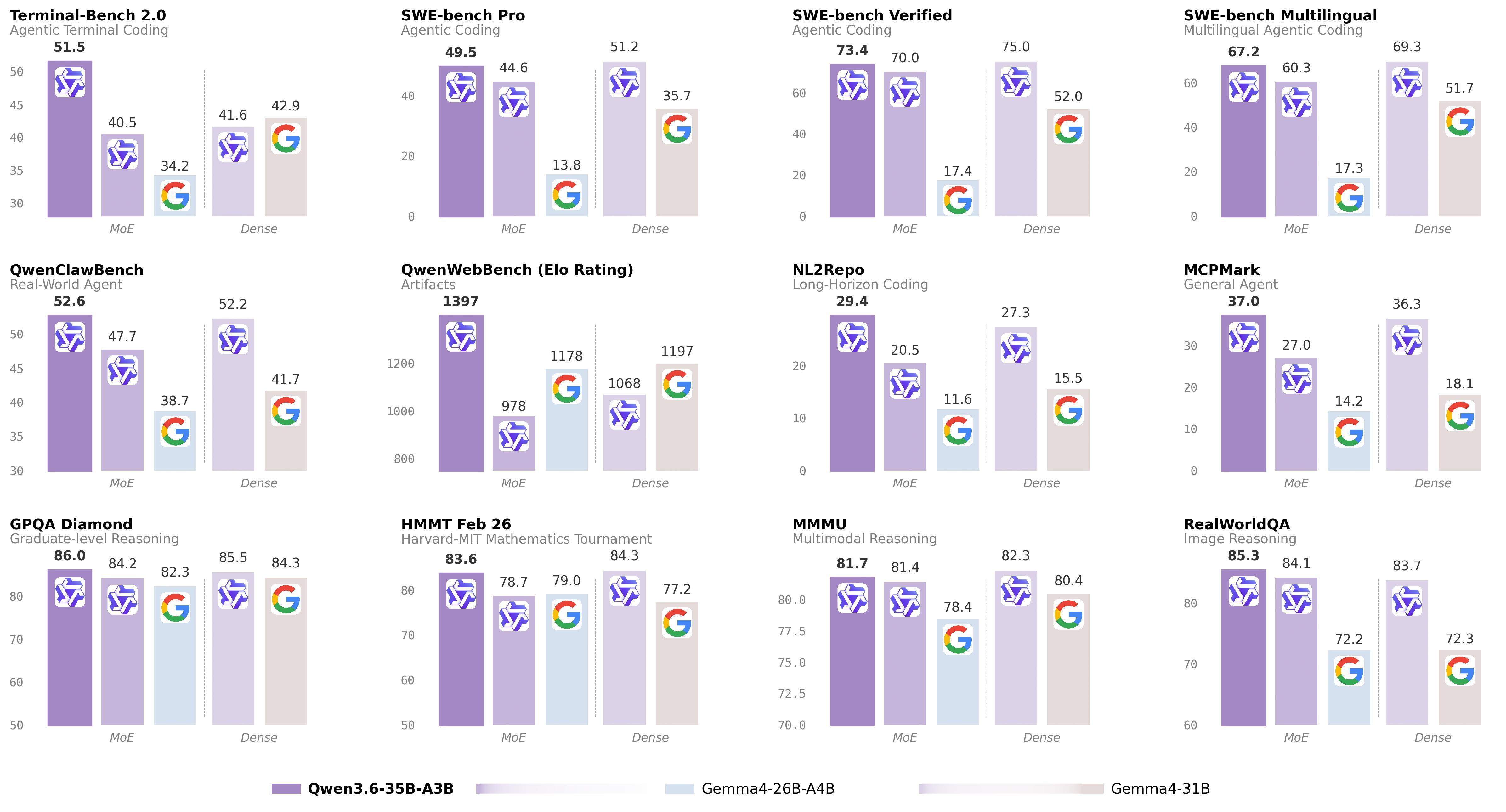
三、官方基准测试对比
1. 编程能力评测(Coding Agent)
评测项目
Qwen3.5-27B
Gemma4-31B
Qwen3.5-35B-A3B
Gemma4-26B-A4B
Qwen3.6-35B-A3B
SWE-bench Verified
75.0
52.0
70.0
17.4
73.4
SWE-bench Multilingual
69.3
51.7
60.3
17.3
67.2
SWE-bench Pro
51.2
35.7
44.6
13.8
49.5
Terminal-Bench 2.0
41.6
42.9
40.5
34.2
51.5
关键发现:
• 超越前代 MoE:相比 Qwen3.5-35B-A3B 有显著提升
• 比肩稠密模型:仅用 3B 激活参数就接近 27B 稠密模型的性能
• 终端任务领先:在 Terminal-Bench 2.0 上以 51.5 分大幅领先所有对手
四、与竞品模型的深度对比
对比 1:Qwen3.6-35B-A3B vs Qwen3.5-27B
维度
Qwen3.5-27B
Qwen3.6-35B-A3B
总参数量
27B
35B
激活参数
27B
3B
推理成本
高
极低
SWE-bench Verified
75.0
73.4
SkillsBench
27.2
28.7
QwenWebBench
1068
1397
理性分析: Qwen3.6-35B-A3B 用 1/9 的计算成本 实现了与 27B 稠密模型相当甚至更优的性能,这是 MoE 架构的巨大胜利。
五、适用场景与选型建议
推荐场景:
智能体编程:在 SWE-bench、Claw-Eval 等编程基准上表现卓越
代码助手:Terminal-Bench 51.5 分,终端任务能力强
网页自动化:QwenWebBench 1397 分,网页交互领先
MCP 生态:MCPMark 37.0 分,模型上下文协议支持优秀
本地化部署:3B 激活参数,消费级 GPU 可流畅运行
高并发服务:低推理成本,适合 API 服务部署
需谨慎场景
极致推理深度:与 GPT-4o、Claude 3.5 Sonnet 等顶级闭源模型仍有差距
超长上下文:官方未明确标注上下文长度,长文档处理需验证
多语言均衡:作为国产模型,中文优化更好,其他语言需测试
六、获取方式
官方提供多种使用途径:
在线体验:Qwen Studio 交互对话
API 调用:阿里云百炼平台,模型名 Qwen3.6-Flash
开源权重:Hugging Face
国内下载:ModelScope
社区交流:Discord
七、总结与评价
核心优势
✓ 效率与性能的完美平衡:3B 激活参数实现 35B 级别的能力
✓ 智能体编程专精:在编程、工具使用、网页交互等任务上表现突出
✓ 开源可商用:完全开源,支持商业使用,社区活跃
✓ 部署门槛低:消费级硬件即可运行,降低 AI 应用准入门槛
✓ 双模式灵活:思考/非思考模式适应不同场景需求
总体评价:
Qwen3.6-35B-A3B 代表了当前开源大模型领域 "效率优先" 技术路线的成熟成果。它不是追求所有维度的最优,而是在 性能、成本、易用性 三者之间取得了精妙的平衡。
本文基于 Qwen 官方技术博客和公开评测数据撰写,具体性能请以实际使用为准。
评论列表