[LG]《The Efficiency Gap in Byte Modeling》C Lee, J N Yan, C Liang, J Shi… [Google DeepMind] (2026)
在字节级语言建模领域,去掉 tokenizer 是一个悬而未决的难题。过去的方法受困于计算开销暴涨,本质原因是原始字节缺少子词边界,模型要自己重建语义单位。
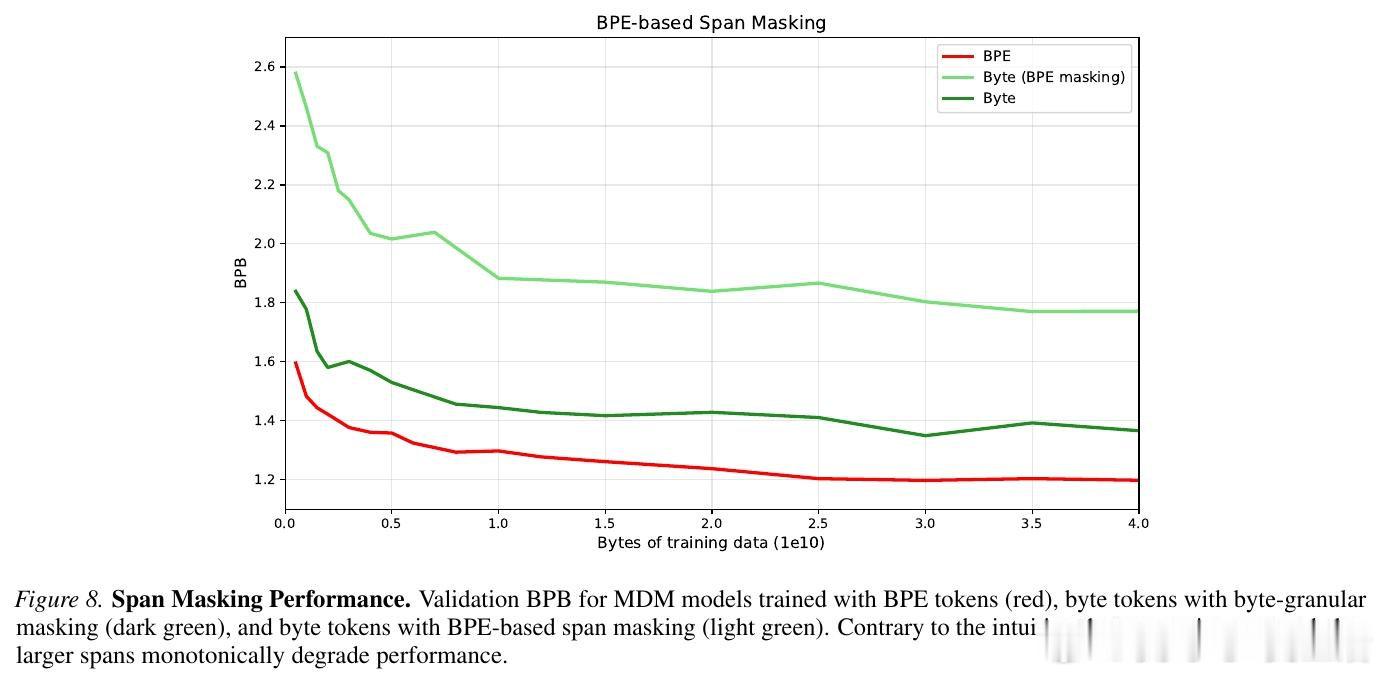
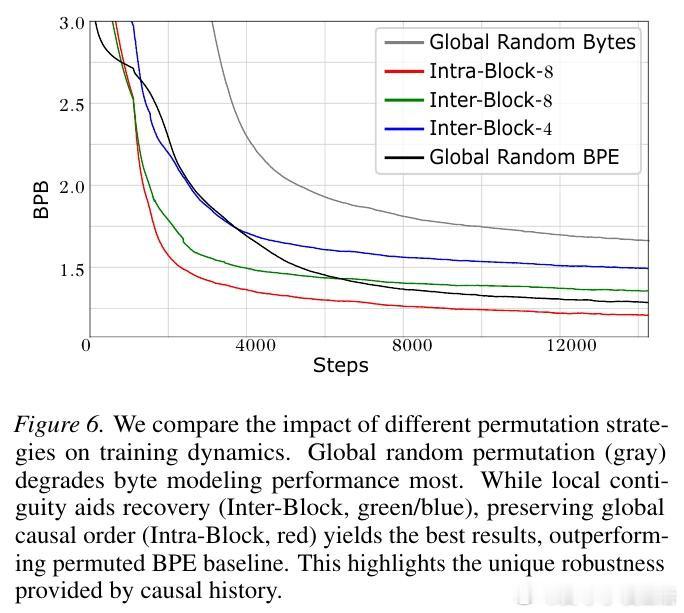
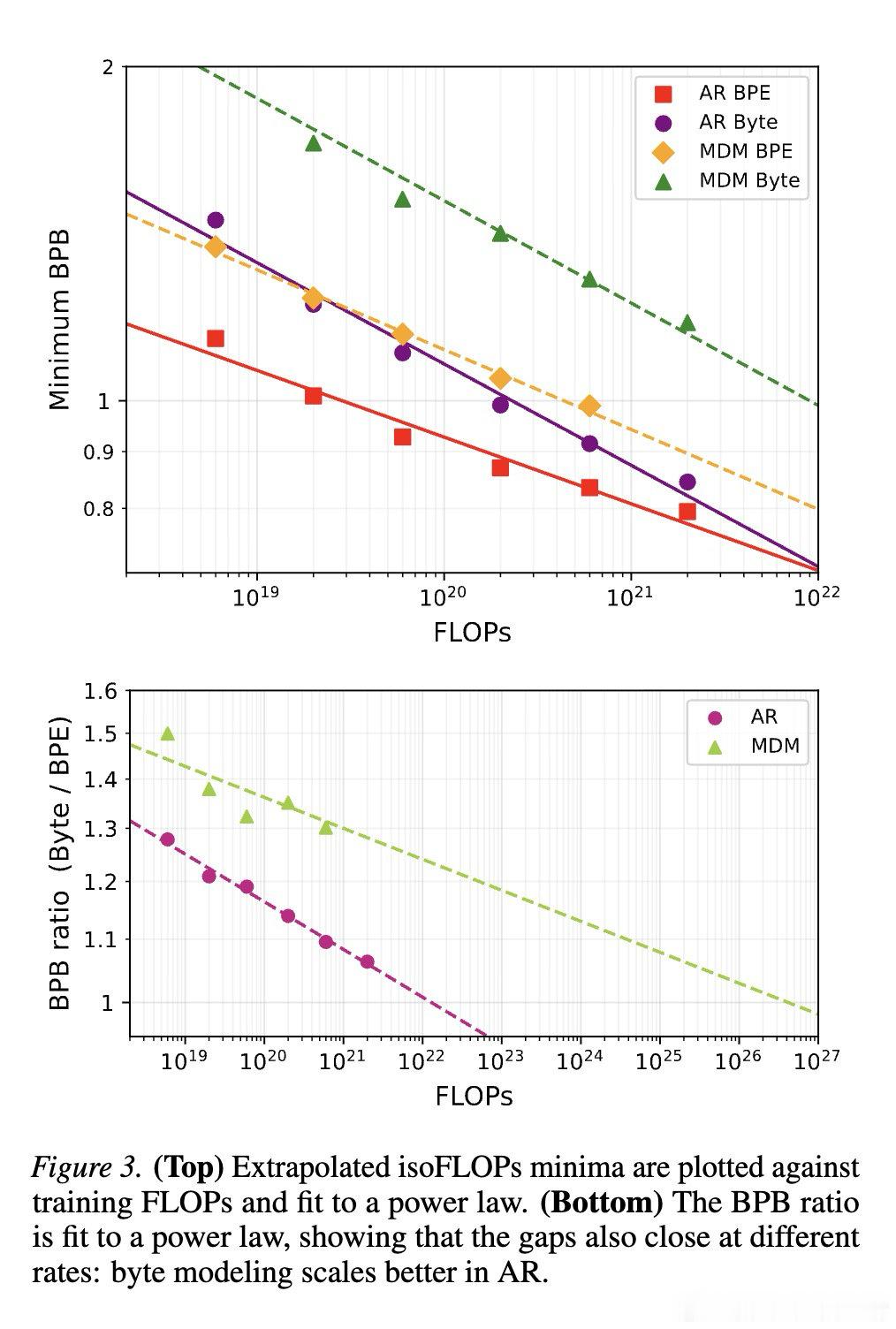
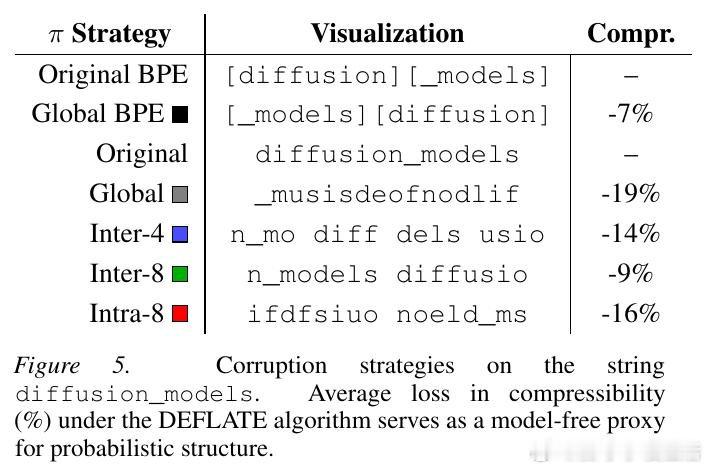
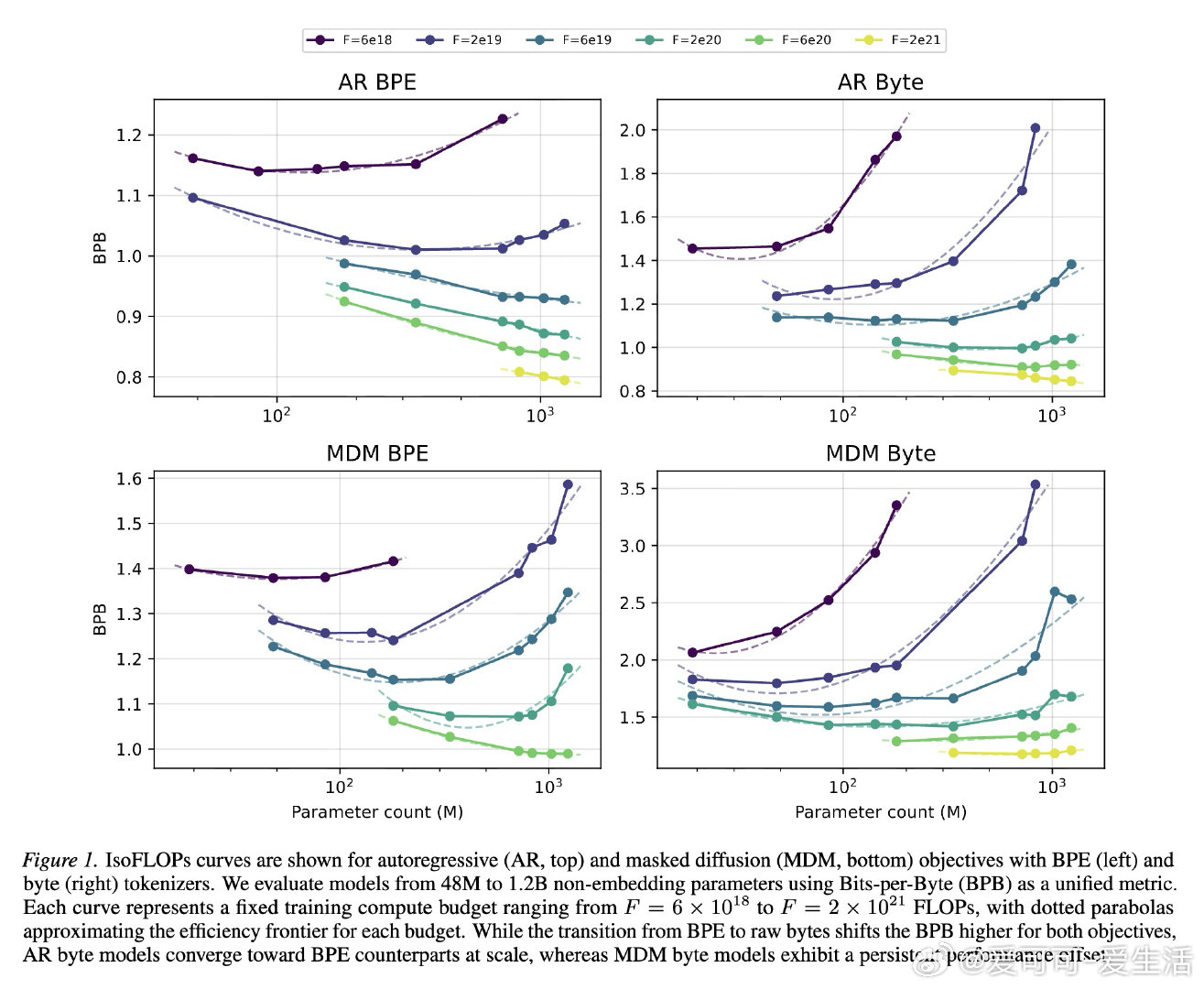
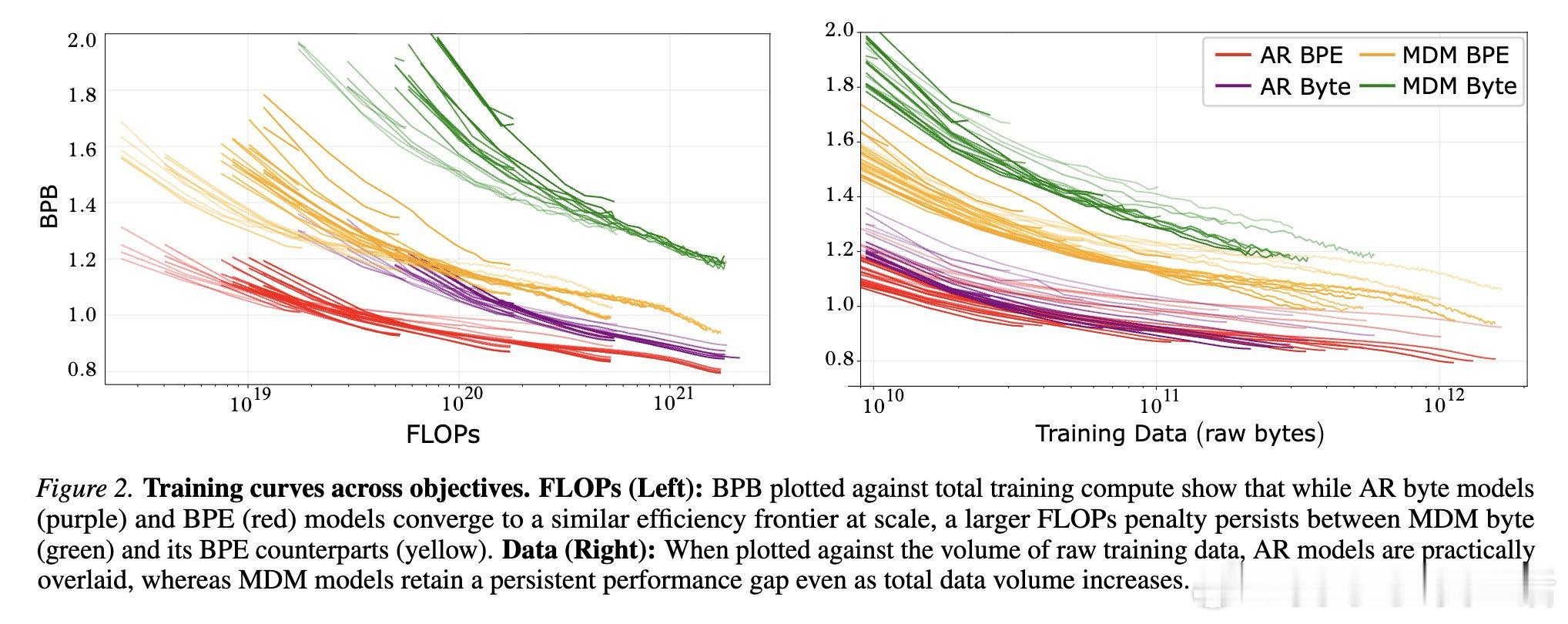
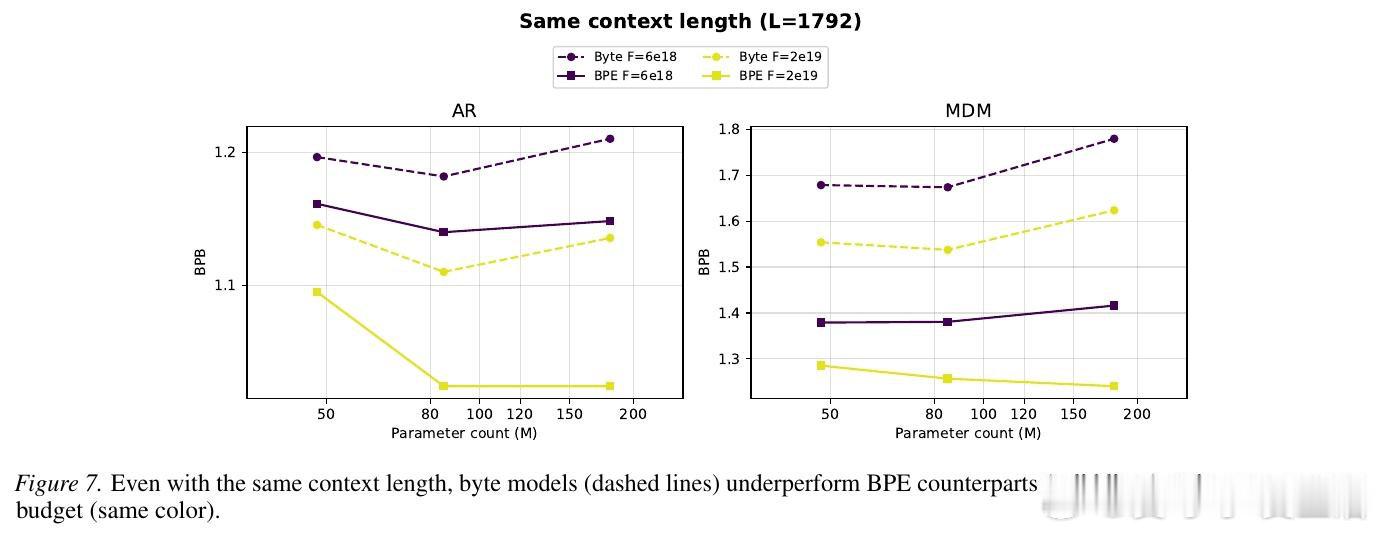
本文的核心洞见是:把字节建模重新看作目标函数与表示粒度的耦合问题。由此,计算匹配缩放与扰动实验这一关键操作揭示:MDM 比 AR 更怕上下文被打碎。
这项工作真正留下的遗产是指出字节建模的代价并非固定,而取决于生成顺序。它为后来者打开的新门是设计新的结构偏置,但尚未跨过的门槛是让字节级 MDM 高效扩展。
arxiv.org/abs/2605.12928 机器学习 人工智能 论文 AI创造营